AWS Partner: Well-Architected Best Practices

AWS Well-Architected Framework Best Practices
Automation: Most of the operational tasks are performed manually. AnyCompany wants to automate some of the operational tasks and provide visibility into important performance metrics, such as memory and disk use. Additionally, a centralized log monitoring for the database and application is needed.
Availability: A highly available architecture is required for any application.
Security: This is a top priority. The more insights available related to this topic, and we can use aws cloud services to provide more security.
Rightsizing Amazon EC2 instances: AnyCompany is not sure about the initial decision to use a t3.micro EC2 instance to host the application. The company does not want to sacrifice performance. AnyCompany people want to do some stress tests for the application, especially because they are expecting an increase in the demand on the application in the near future.
Cost: Some applications are not using approved instance types in accordance with AnyCompany’s architecture standard. This has increased unnecessary cost due to over-provisioned resources in non-production environments.
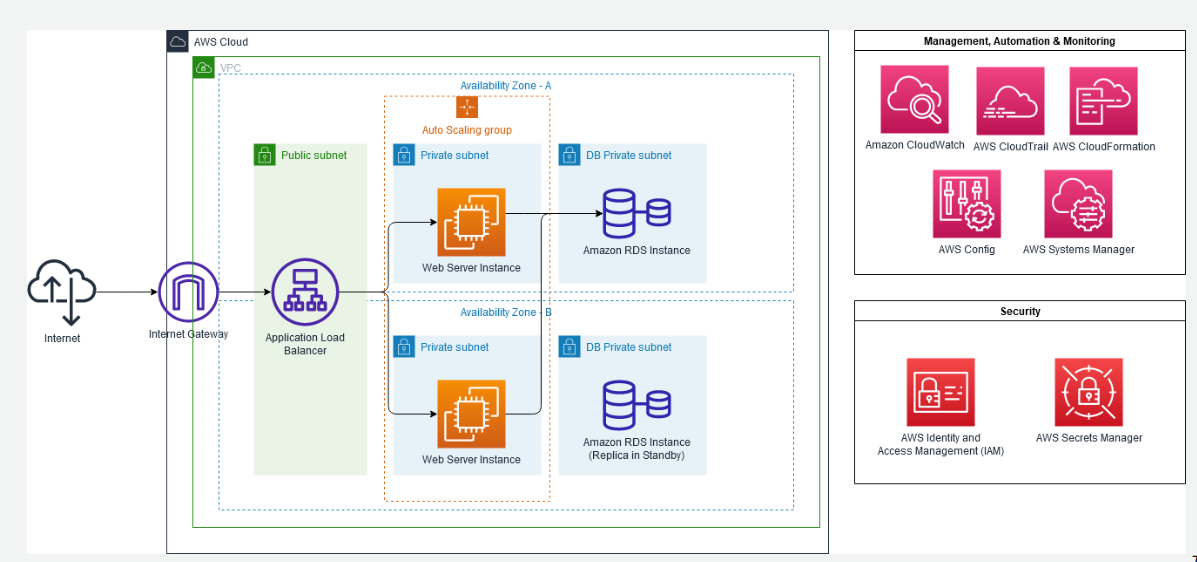
The architecture is an Amazon VPC containing 2 Availability Zones. There are 6 total subnets in the environment, with each Availability Zone having 3 of the subnets. The subnets are labelled and divided per Availability Zone as such: 1 public subnet, 1 private subnet, and 1 db private subnet. Each of the private subnets is part of an Auto Scaling group and contains 1 web server each. Each of the db private subnets contain 1 Amazon RDS instance each. Internet traffic flows into an internet gateway, to an application load balancer residing in the public subnets, then to the auto scaling group in the private subnets, and finally to the Amazon RDS primary instance in the db private subnet. Supporting management, automation & monitoring services for the environment are: Amazon CloudWatch, AWS CloudTrail, AWS CloudFormation, AWS Config, and AWS Systems Manager. Supporting security services for the environment are AWS Identity and Access Management, and AWS Secrets Manager.
We can see examples for these 5 pillars with the above architecture
Operation Excellence Pillar
Security Pillar
Reliability Pillar
Performance Pillar
Cost Optimization Pillar
Operational Excellence Pillar
The ability to support development and run workloads effectively, gain insight into their operations, and to continuously improve supporting processes and procedures to deliver business value.
💠 My aim is to automate the process of log collection and metric gathering for its Amazon EC2 instances.
Key Principles:
Perform Operations as Code: Use infrastructure as code (IaC) tools like AWS CloudFormation or Terraform to define and deploy infrastructure.
Analyze Operations Data: Leverage AWS CloudWatch to collect and analyze operational data, such as logs and metrics. Create dashboards and set up alarms to monitor the health of your resources.
- Set up monitoring using AWS CloudWatch to collect and visualize metrics. Use AWS CloudTrail for auditing and tracking changes in your AWS environment.
Learn from Operational Failures: Implement post-incident reviews (PIRs) after system failures or incidents. Use tools like AWS CloudTrail to understand what happened during an incident and update processes accordingly.
Document and Share Knowledge: Use AWS Systems Manager Documents to automate operational procedures. Create and maintain documentation that is easily accessible to the team, ensuring knowledge sharing.
Make Frequent, Small, Reversible Changes: Implement a continuous integration and continuous deployment (CI/CD) pipeline to automate the deployment of small, incremental changes. This reduces the risk associated with large, infrequent deployments.
Resource Tagging and Organization: Implement a consistent tagging strategy for resources to facilitate cost allocation, resource tracking, and management.
Based upon this example in the architecture, we can implement below points to follow the operation excellence pillar
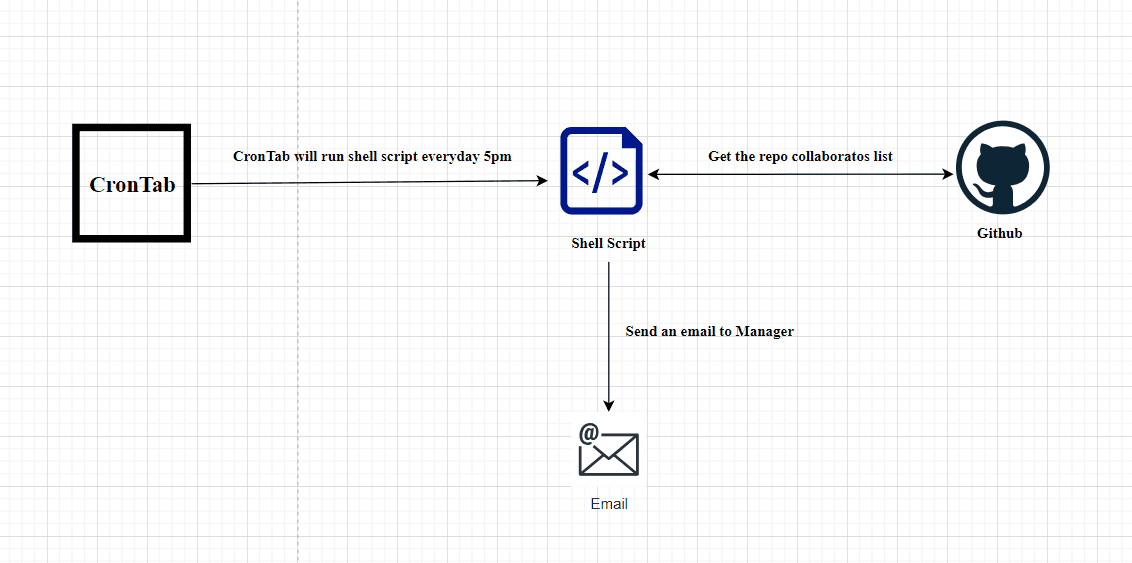
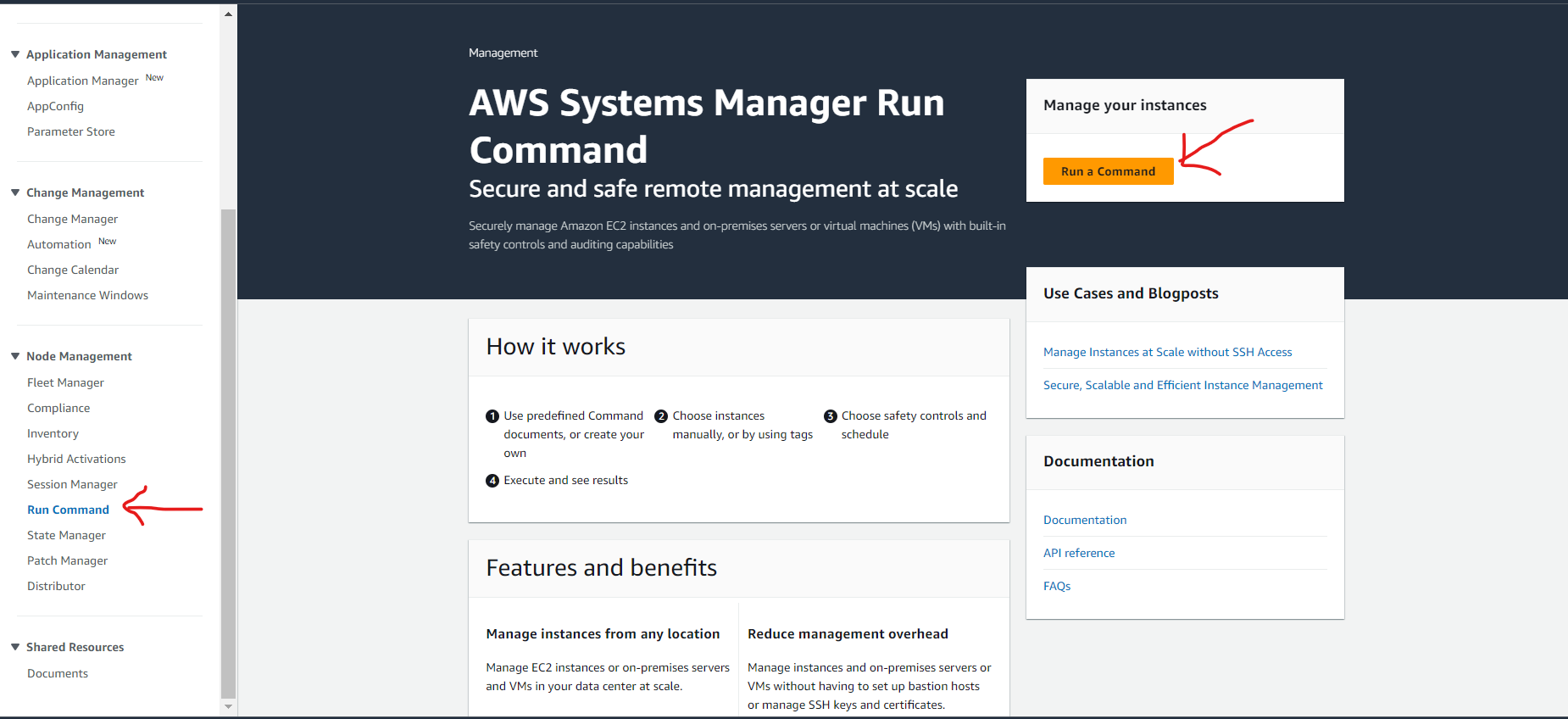
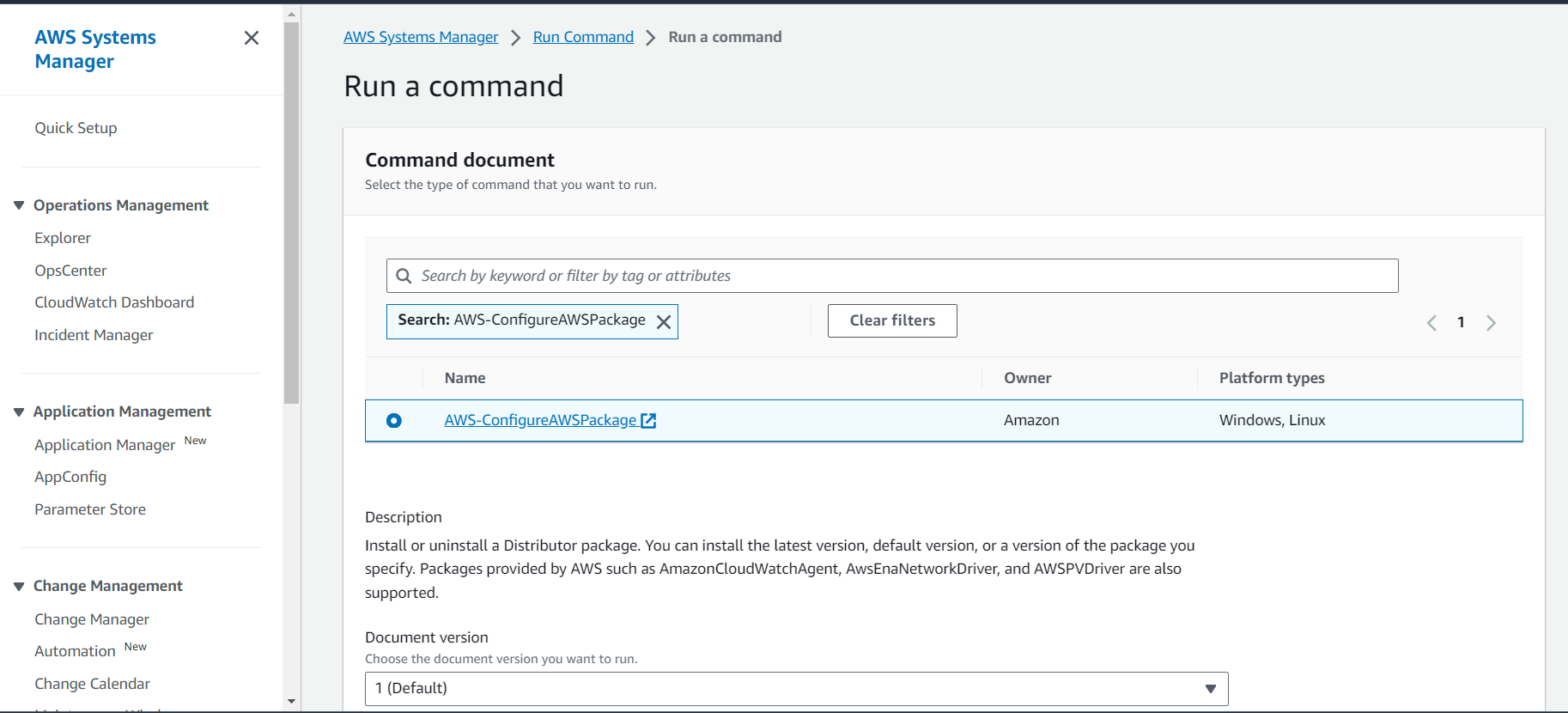
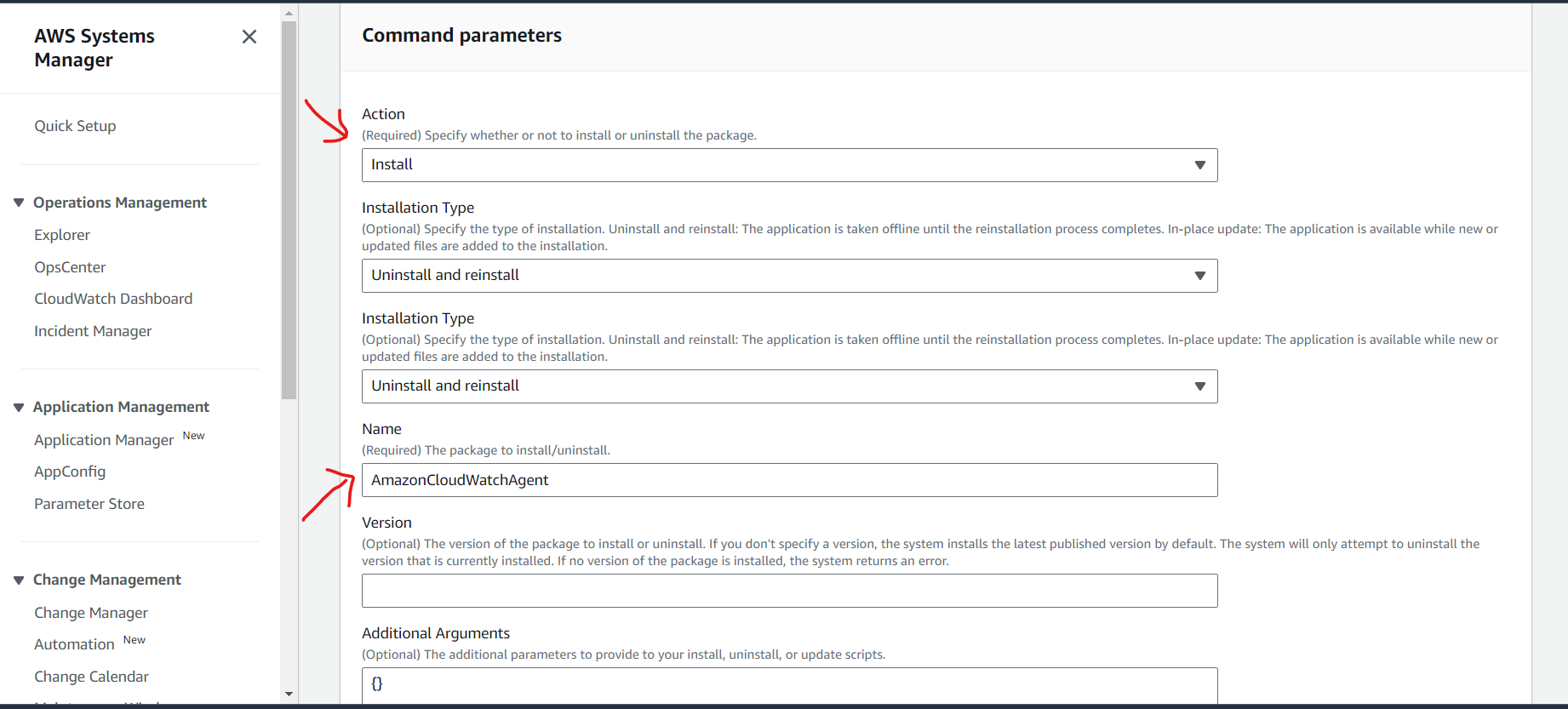
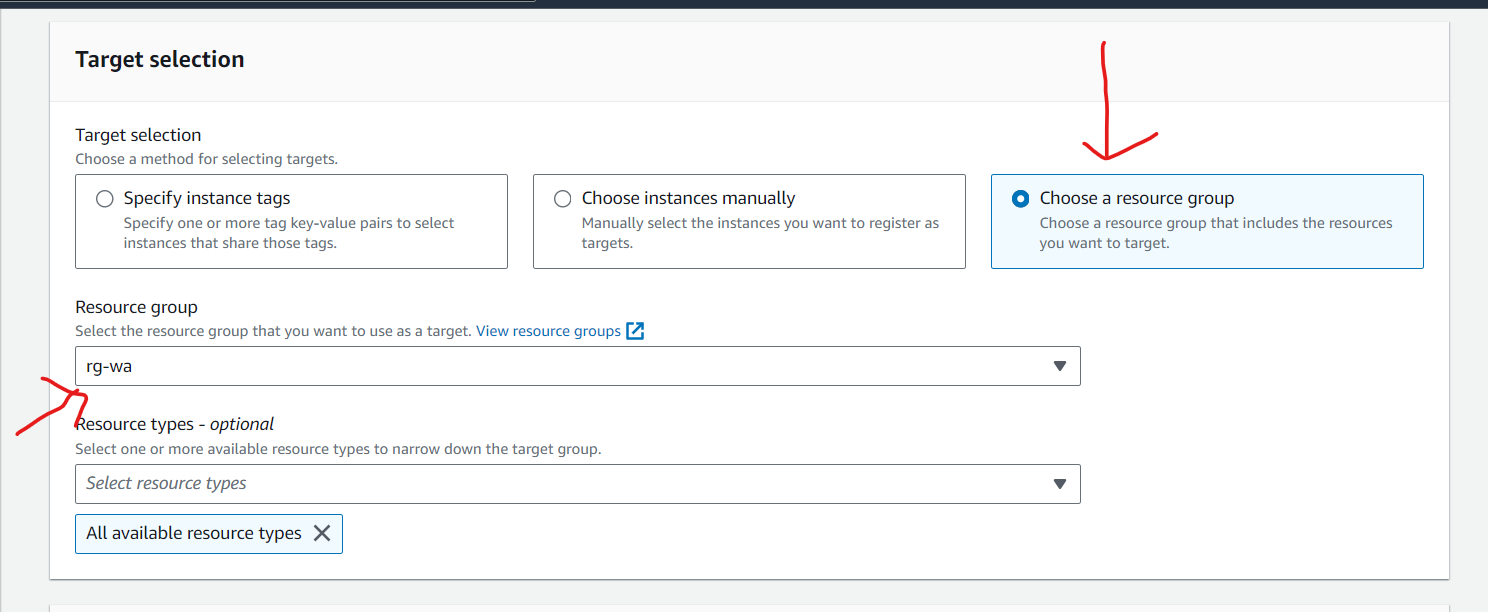
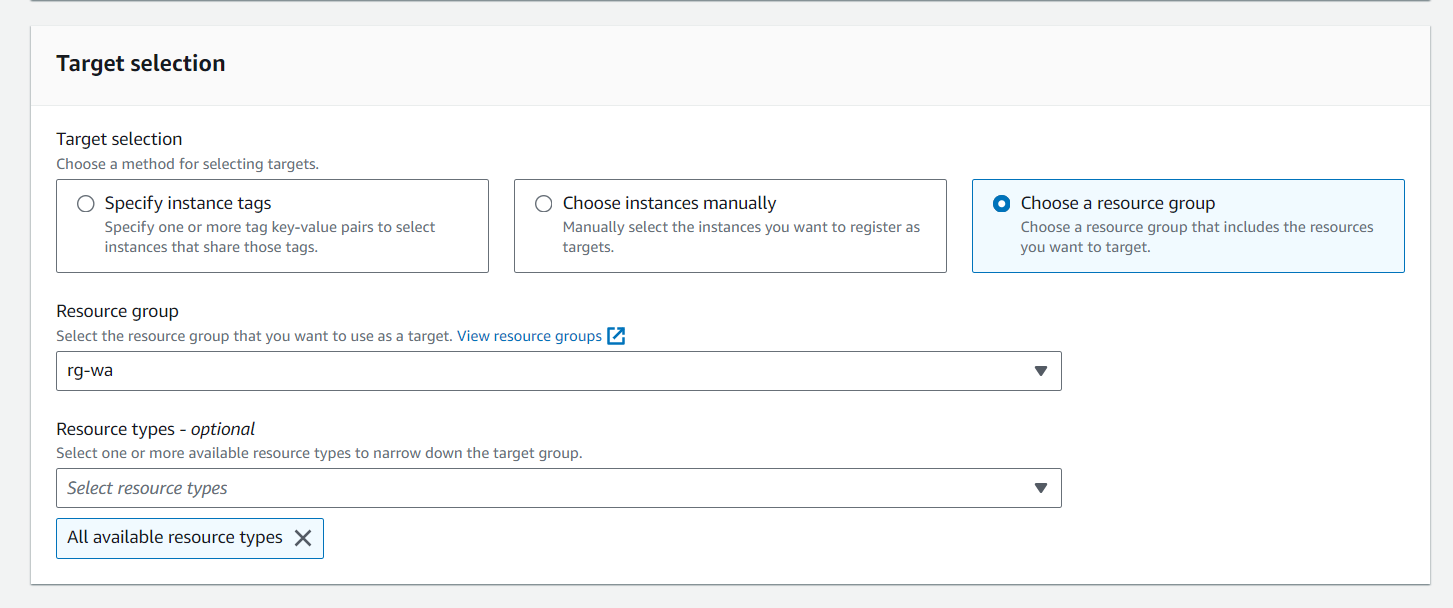
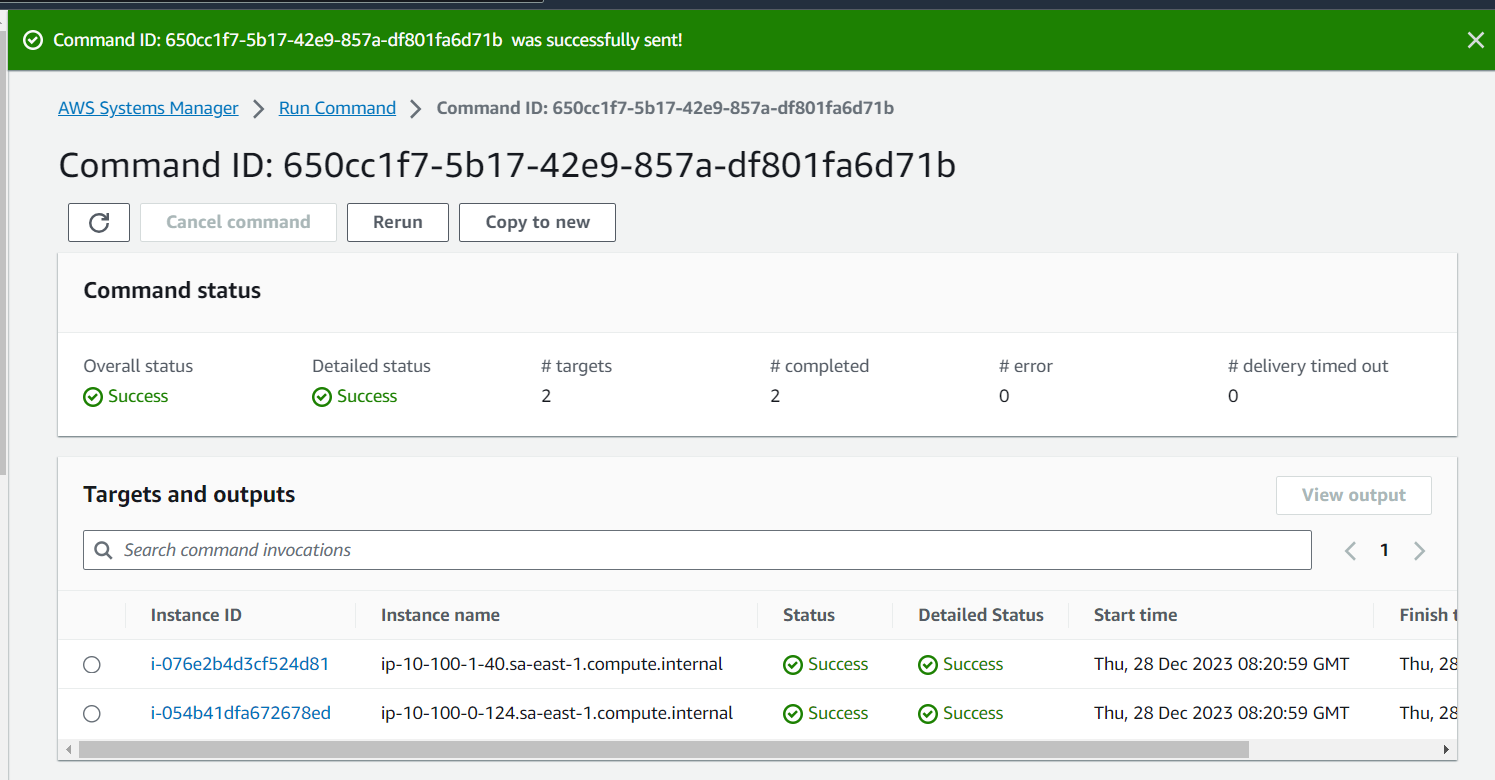
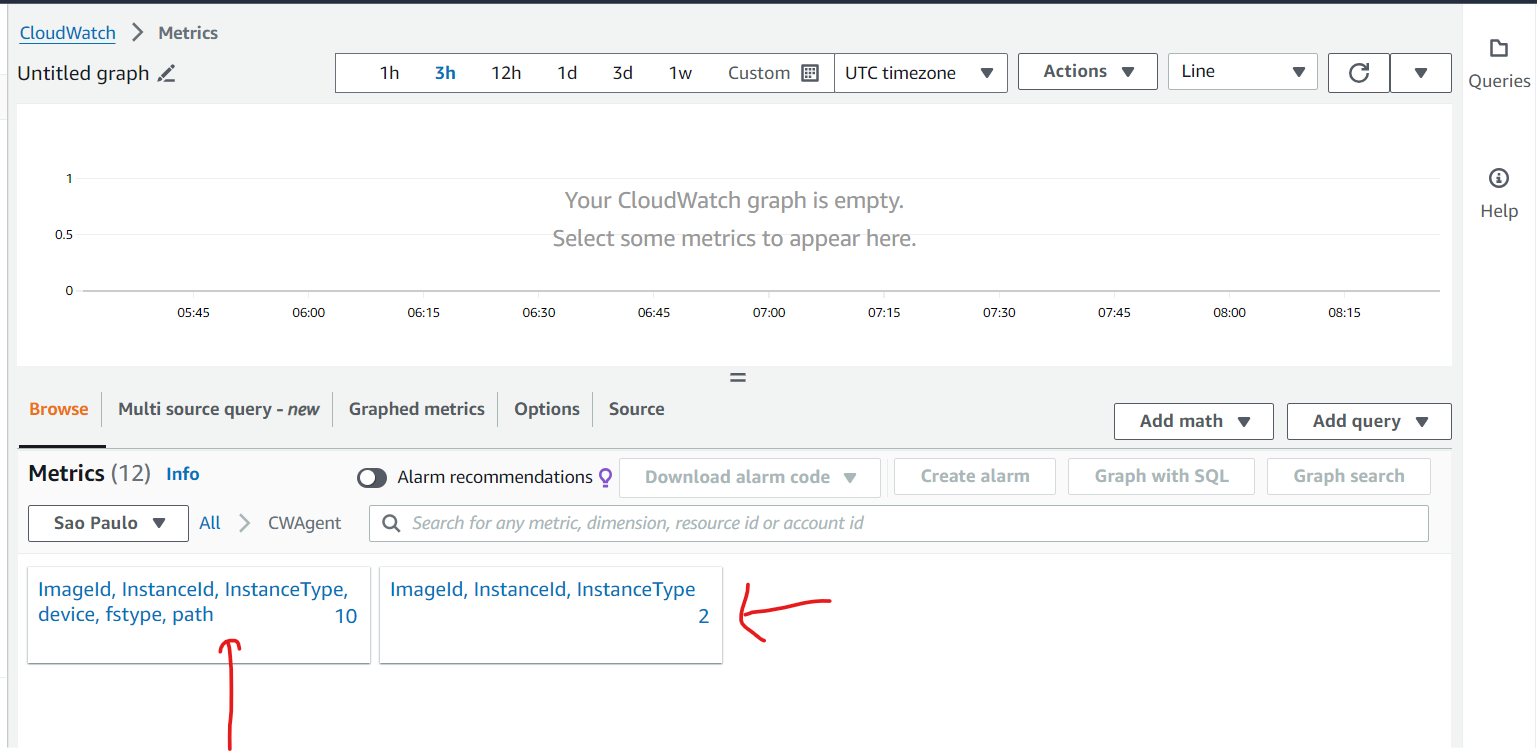
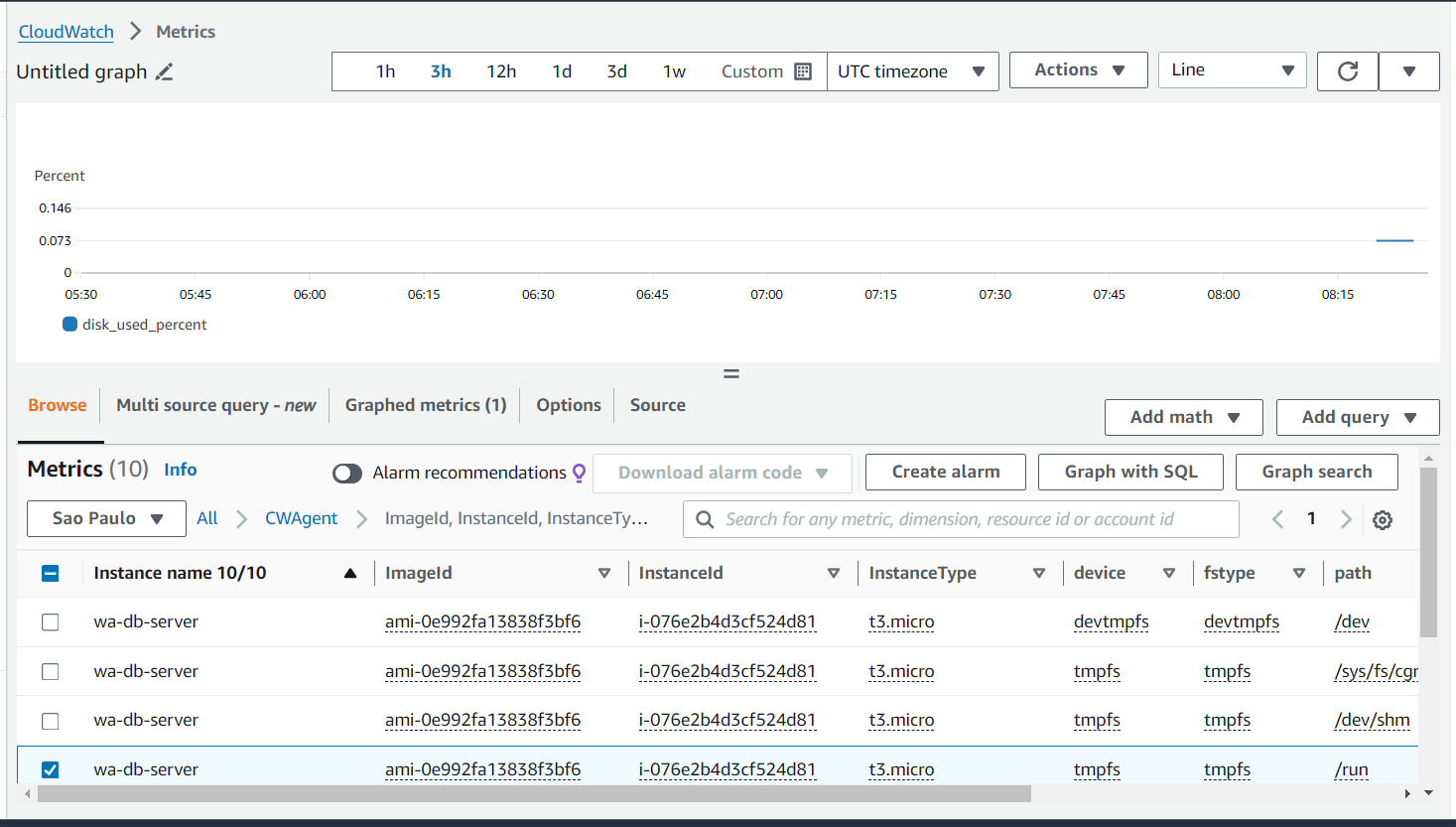
created an AWS Resource Group consisting of two Amazon Elastic Compute Cloud (Amazon EC2) instances and use the “Run command” capability of AWS Systems Manager to install the Amazon CloudWatch agent for collecting logs and getting some additional metrics.
Add custom tags to Amazon EC2 instances.
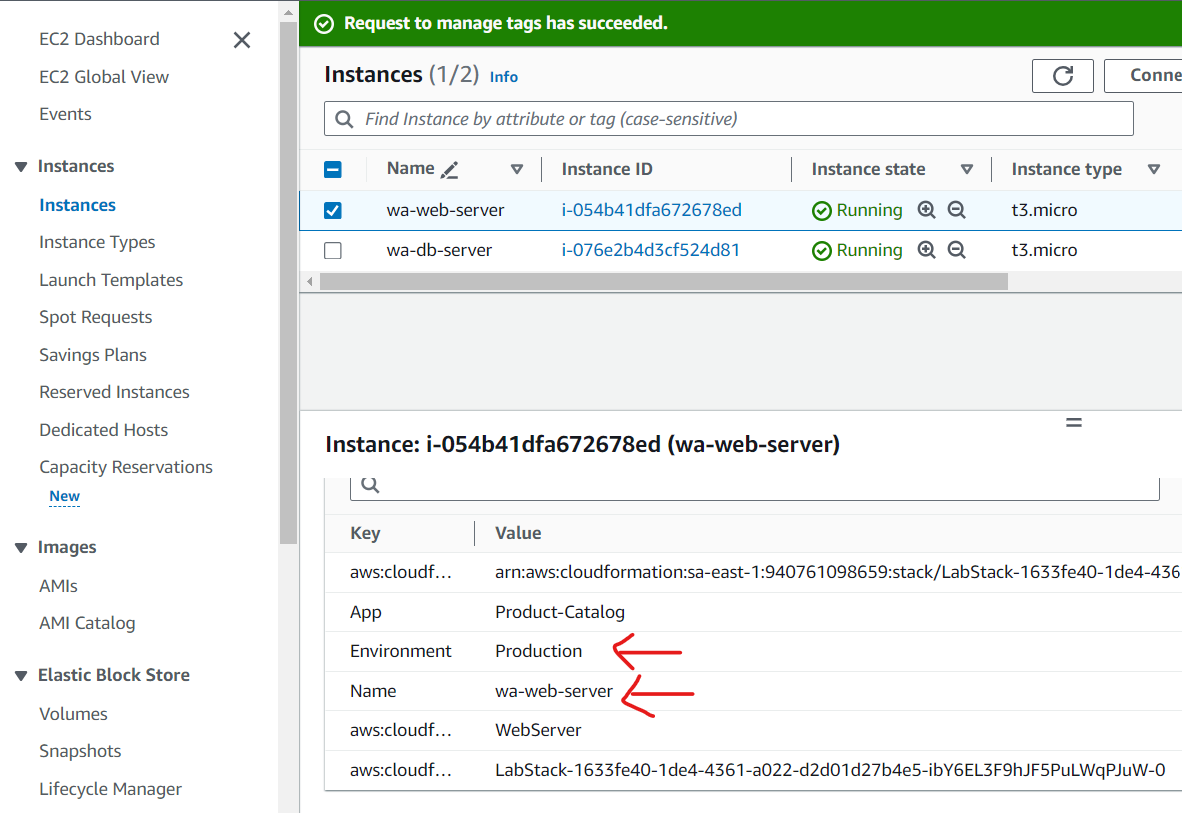
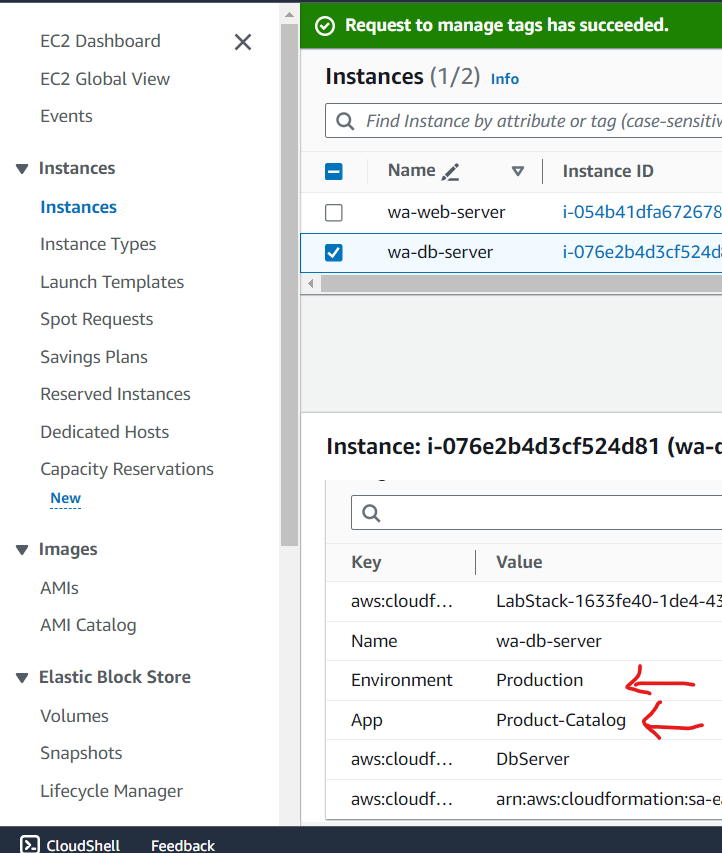
- Create an AWS Resource Group for specific Amazon EC2 instances.
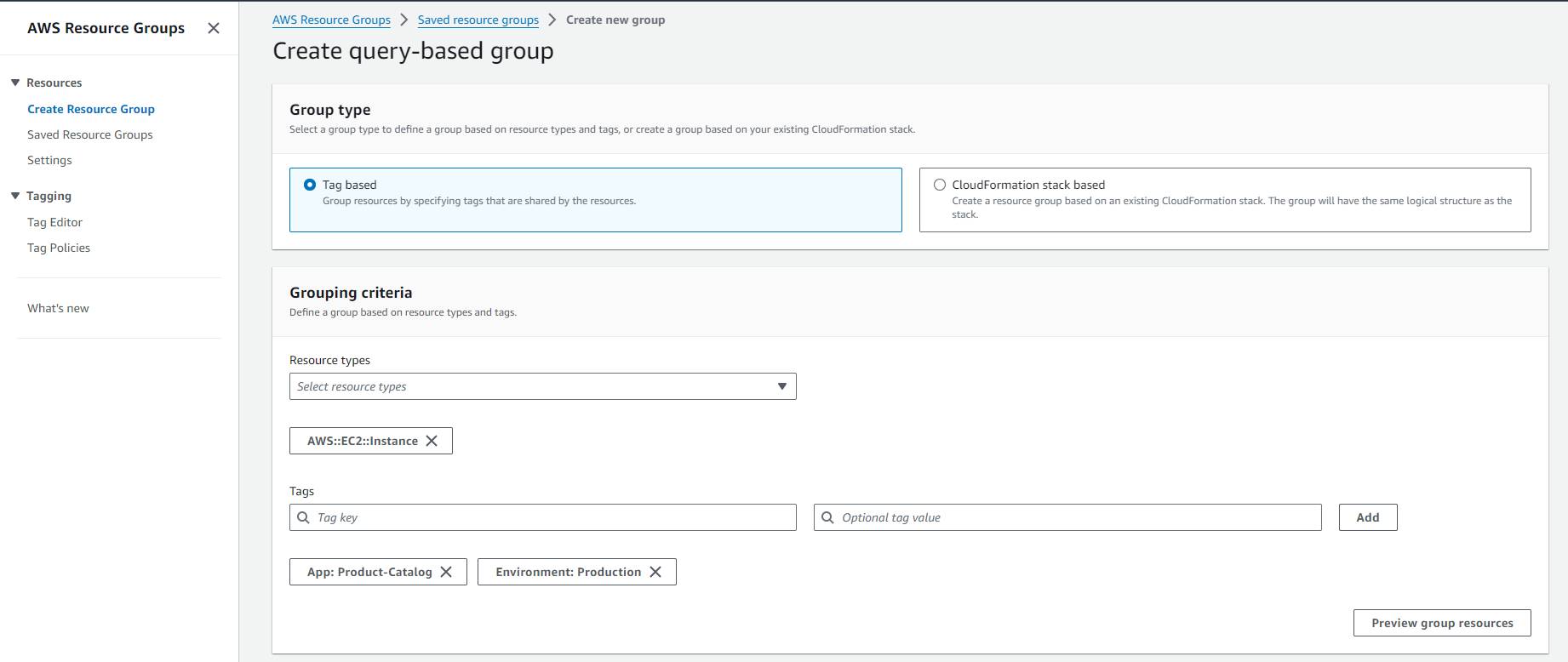
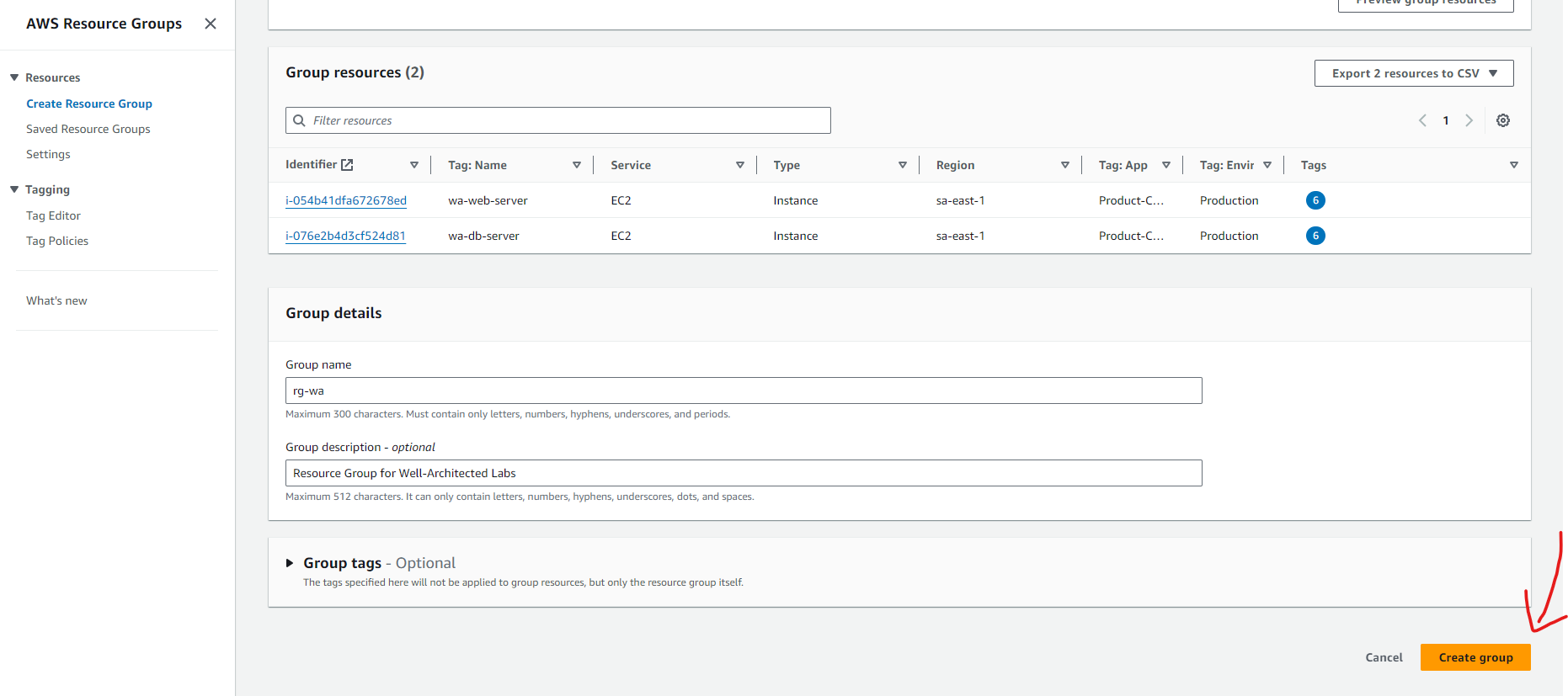
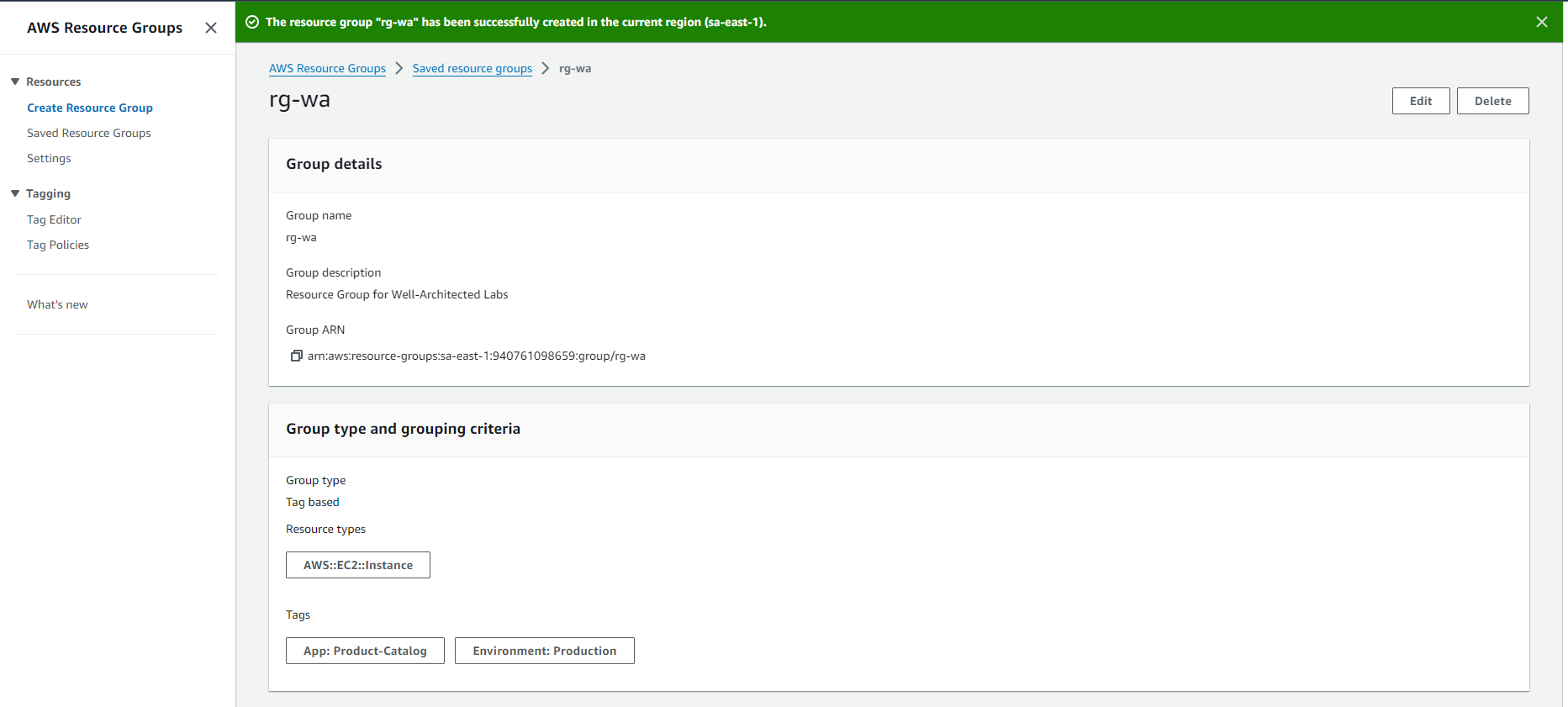
- Use AWS Systems Manager for configuration of Amazon EC2 instances.
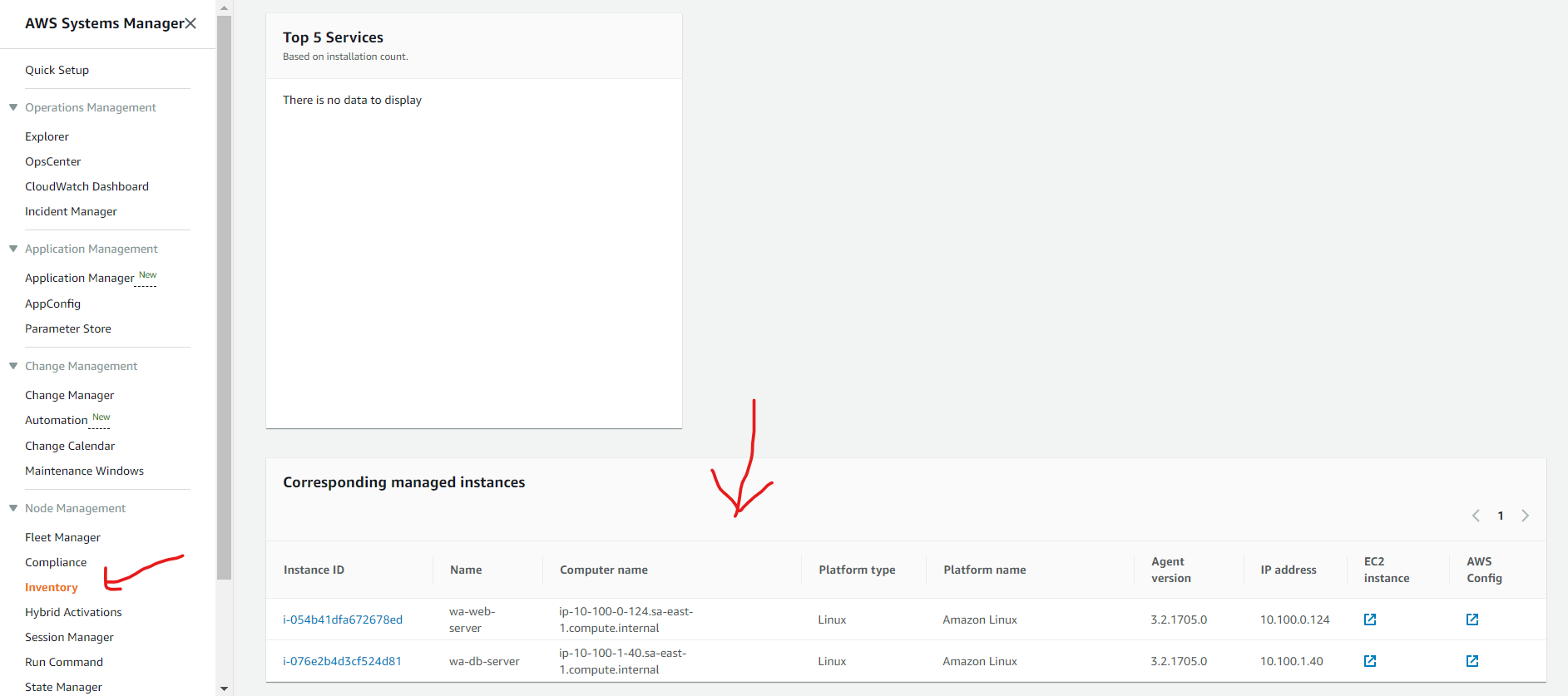
- Install and start Amazon CloudWatch agent using AWS Systems Manager.
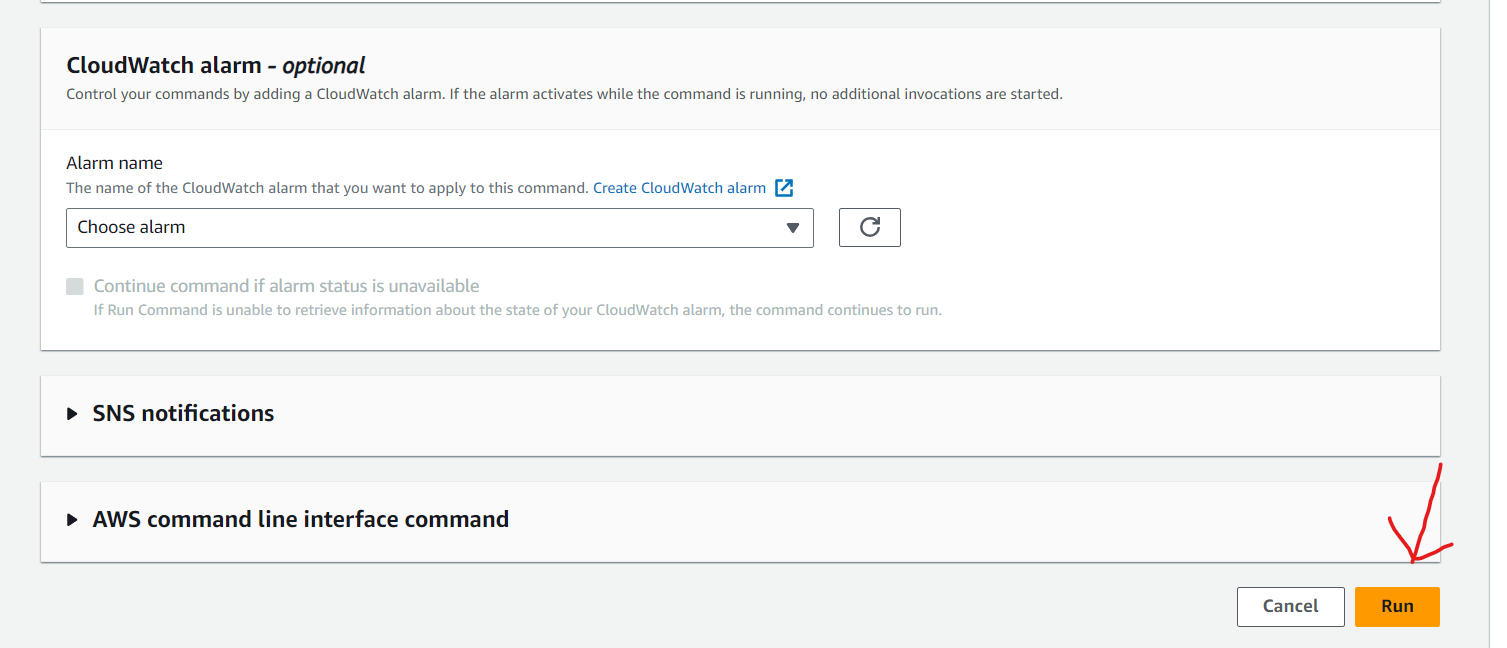
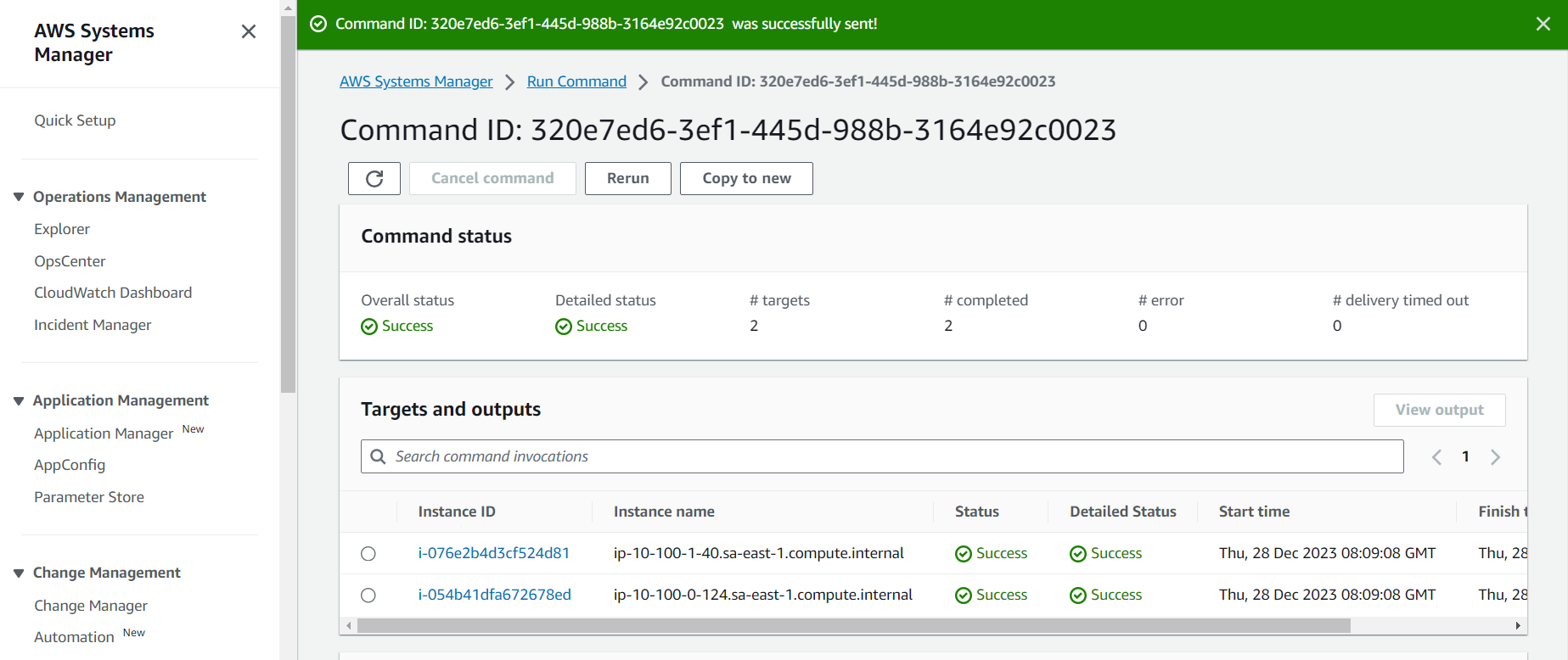
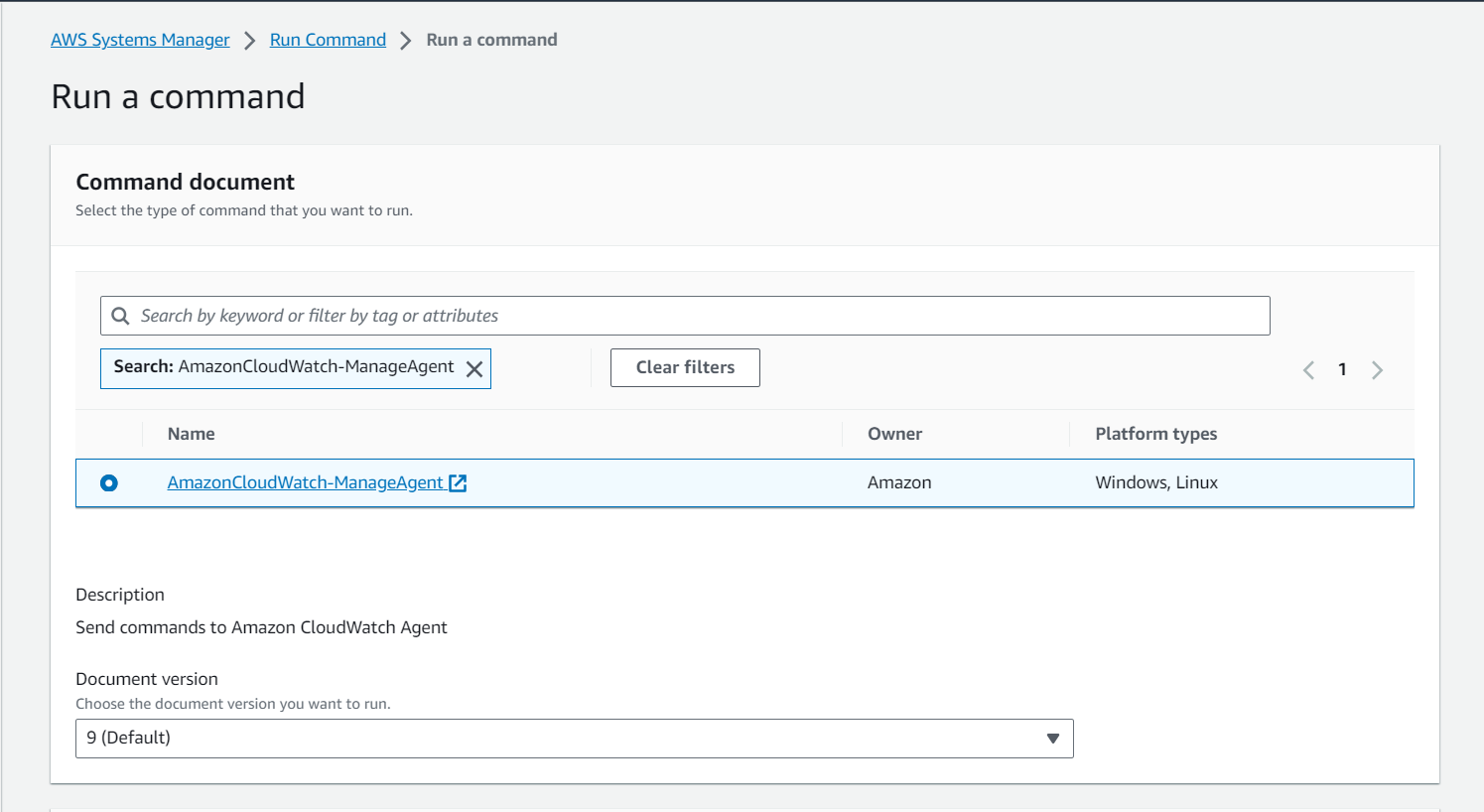
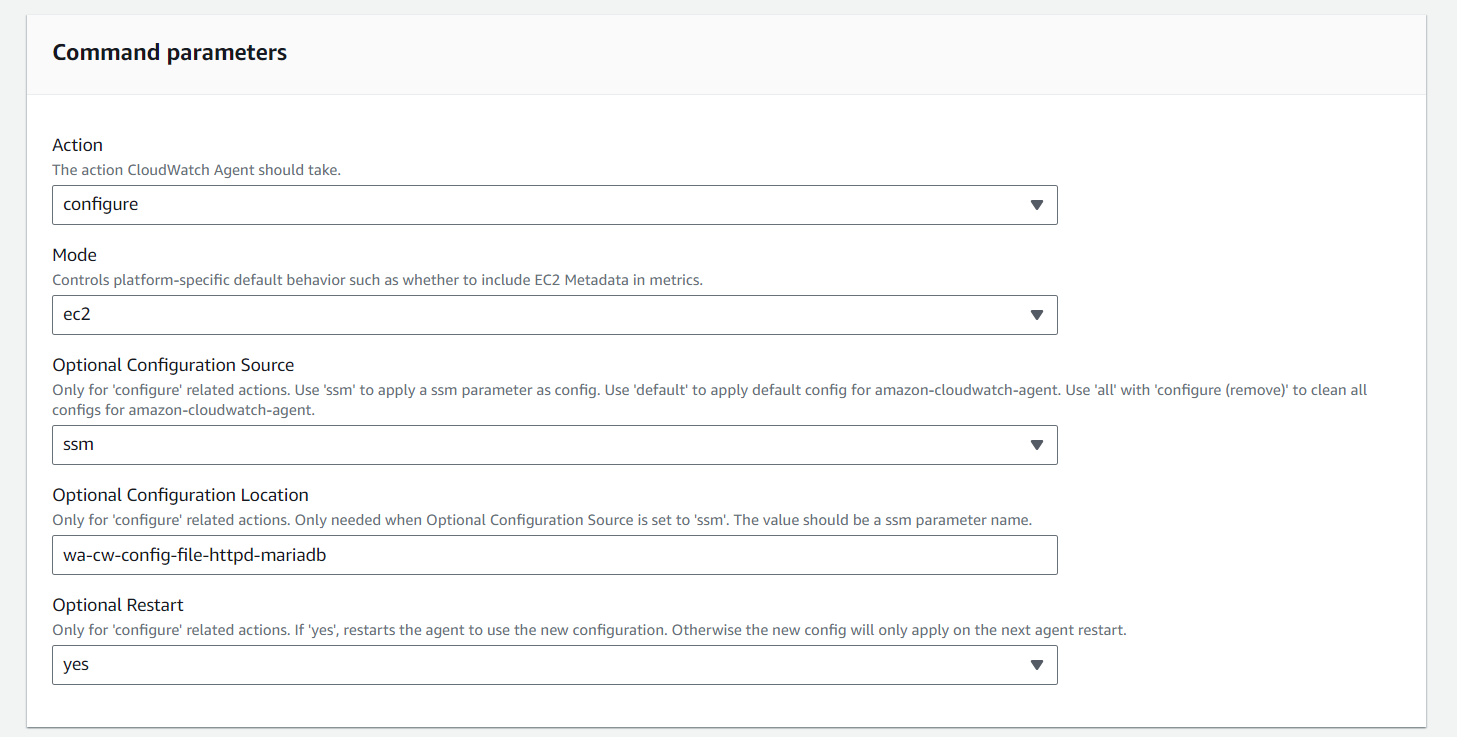
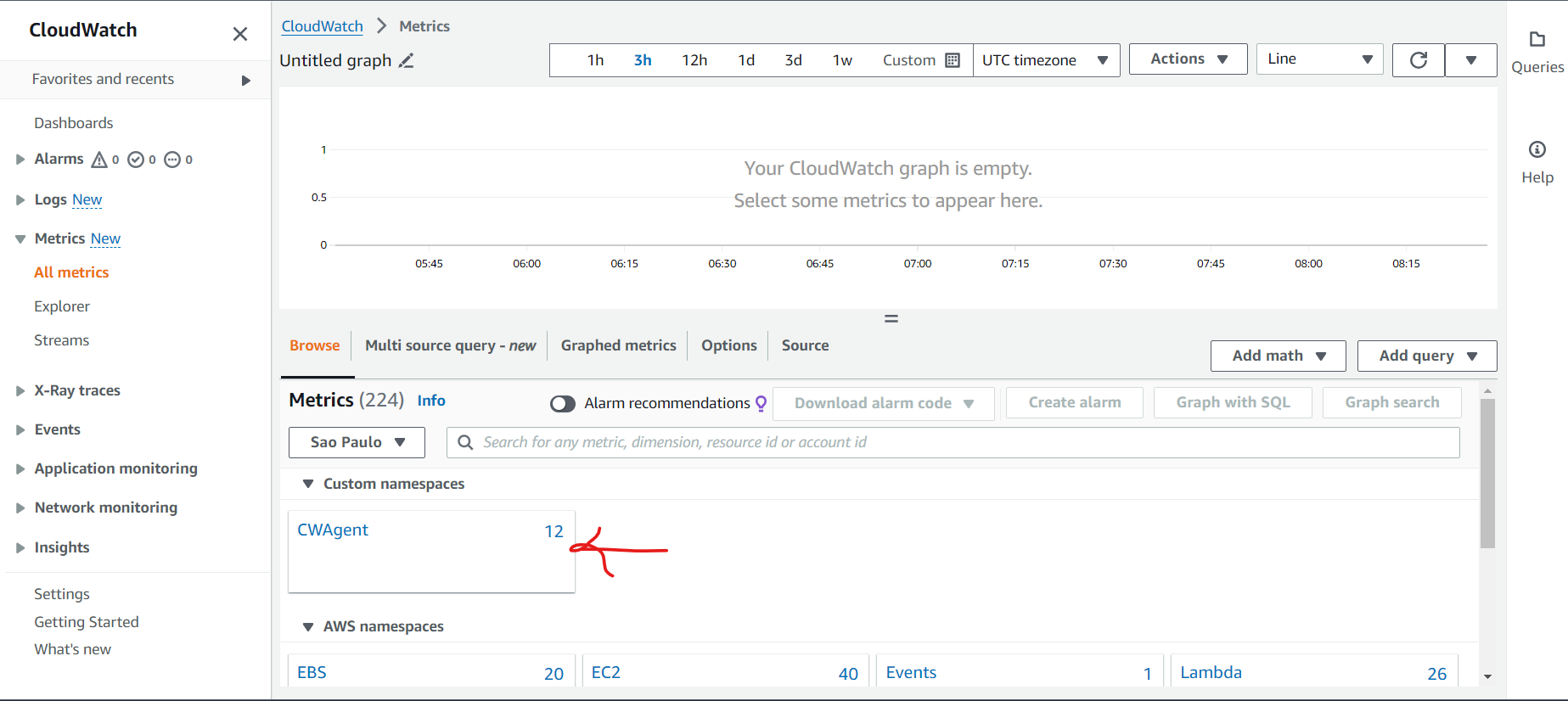
- Validate custom metrics and log groups for Amazon EC2 instances in Amazon CloudWatch.
Some other examples for Operational Excellence Pillar
Infrastructure as Code (IaC): Use tools like AWS CloudFormation or Terraform to define and provision infrastructure.
Automated Testing and Deployment: Implement CI/CD pipelines using AWS CodePipeline, AWS CodeBuild, and AWS CodeDeploy to automate testing and deployment processes
Monitoring and Logging: Set up monitoring using AWS CloudWatch to collect and visualize metrics. Use AWS CloudTrail for auditing and tracking changes in your AWS environment.
Incident Response and Post-Incident Analysis: Post-incident reviews to learn from failures and improve operational processes. Use AWS tools like AWS Config for tracking changes and AWS X-Ray for tracing requests.
Resource Tagging and Organization: Implement a consistent tagging strategy for resources to facilitate cost allocation, resource tracking, and management.
🔶 Outcome:
🔹 Log collection and metric gathering processes are automated.
🔹 CloudWatch agent is successfully installed on EC2 instances.
🔹 Custom tags are applied to EC2 instances for improved resource tracking.
Reliability Pillar
It focuses on the ability of a system to recover from failures and meet customer expectations regarding availability and performance. Ensuring reliability involves designing architectures that can withstand failures and disruptions
💠I want to improve the reliability of architecture by deploying resources across multiple Availability Zones and migrating a database to Amazon RDS for high availability.
Key Principles:
Test Recovery Procedures: Regularly simulate failures, such as shutting down instances or services, to test your system's recovery procedures. Use tools like AWS CloudFormation to automate the creation of test environments.
Automatically Recover from Failures: Implement auto-scaling groups and load balancing to distribute incoming traffic across multiple instances. Use AWS Elastic Load Balancing (ELB) and Amazon EC2 Auto Scaling to automatically adjust resources based on demand.
Scale Horizontally to Increase System Availability: Design your system to scale horizontally by adding more instances rather than scaling vertically. This can be achieved using services like Amazon EC2 Auto Scaling or AWS Elastic Beanstalk.
Stop Guessing Capacity: Use AWS services like Amazon CloudWatch to monitor the performance of your applications and automatically scale resources based on demand. This avoids over-provisioning and under-provisioning of resources.
Manage Change in Automation: Use Infrastructure as Code (IaC) tools like AWS CloudFormation or Terraform to automate the deployment and modification of infrastructure. This ensures consistency and reduces the risk of manual errors.
Based upon this example we can implement below points to follow the reliability pillar
Expand an existing architecture to a second Availability Zone.
Add subnets to an Availability Zone.
Deploy Amazon RDS using a multiple Availability Zones configuration.
Update Parameter Store, a capability of AWS Systems Manager, for database credentials.
Create an Application Load Balancer and a target group.
Migrate a database from a standalone instance to Amazon RDS using Systems Manager Run Command.
Create a launch template.
Create an Amazon EC2 Auto Scaling group.
Create Amazon Route 53 health checks.
Test your application reliability by terminating instances from the AWS Auto Scaling group.
Some other examples for Reliability Pillar
Multi-AZ Deployments: Design applications to run in multiple Availability Zones (AZs) to ensure high availability.
Backup and Restore Procedures: Implement regular backup procedures for critical data. Use AWS services like Amazon S3 for durable and scalable storage, and Amazon Glacier for long-term archival.
Automated Failover and Load Balancing: Configure auto-scaling groups and use load balancers to distribute incoming traffic across multiple instances. Implement automated failover for critical components using services like Amazon Route 53 and AWS Global Accelerator.
Fault-Tolerant Architectures: Design architectures with fault tolerance in mind. For example, use Amazon S3 for object storage with built-in redundancy, or leverage AWS Lambda for serverless computing that automatically scales and manages underlying infrastructure.
🔶 Outcome:
🔹 Architecture is now deployed across multiple Availability Zones.
🔹 Amazon RDS instances configured for high availability.
🔹 Application Load Balancer distributes traffic for better reliability.
Security Pillar
The security pillar describes how to take advantage of cloud technologies to protect data, systems, and assets in a way that can improve your security posture.
💠 We prioritizes security and wants to strengthen network security and access management for its AWS environment.
Key Principles:
Implement a Strong Identity Foundation: Use AWS Identity and Access Management (IAM) to manage and control access to AWS resources. Follow the principle of least privilege, ensuring that users and systems have only the permissions necessary for their specific tasks.
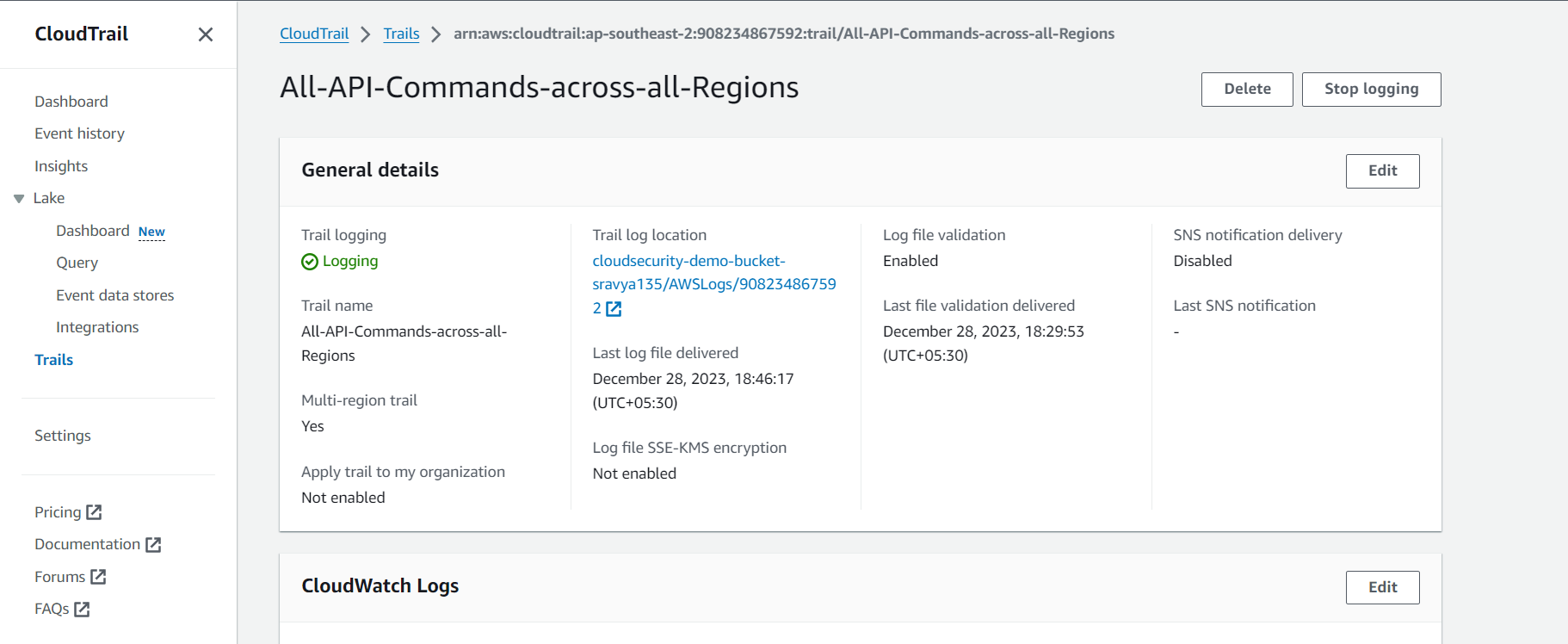
Enable Traceability: Use AWS CloudTrail to log API calls and monitor account activity. Enable AWS Config to assess, audit, and evaluate the configurations of AWS resources over time.
Apply Security at All Layers: Implement security measures at every layer of your architecture, including network security, data encryption, and application security. Use Amazon Virtual Private Cloud (VPC) for network isolation and security groups for fine-grained control of inbound and outbound traffic.
Automate Security Best Practices: Leverage automation tools like AWS Config Rules and AWS Security Hub to continuously monitor and enforce security best practices. Automate the deployment of security controls using Infrastructure as Code (IaC) tools like AWS CloudFormation.
Protect Data in Transit and at Rest: Use encryption mechanisms such as HTTPS for data in transit and AWS Key Management Service (KMS) for data at rest. Implement encryption for sensitive data stored in Amazon S3, Amazon RDS, and other storage services.
Based upon this example we can implement below points to follow the security pillar
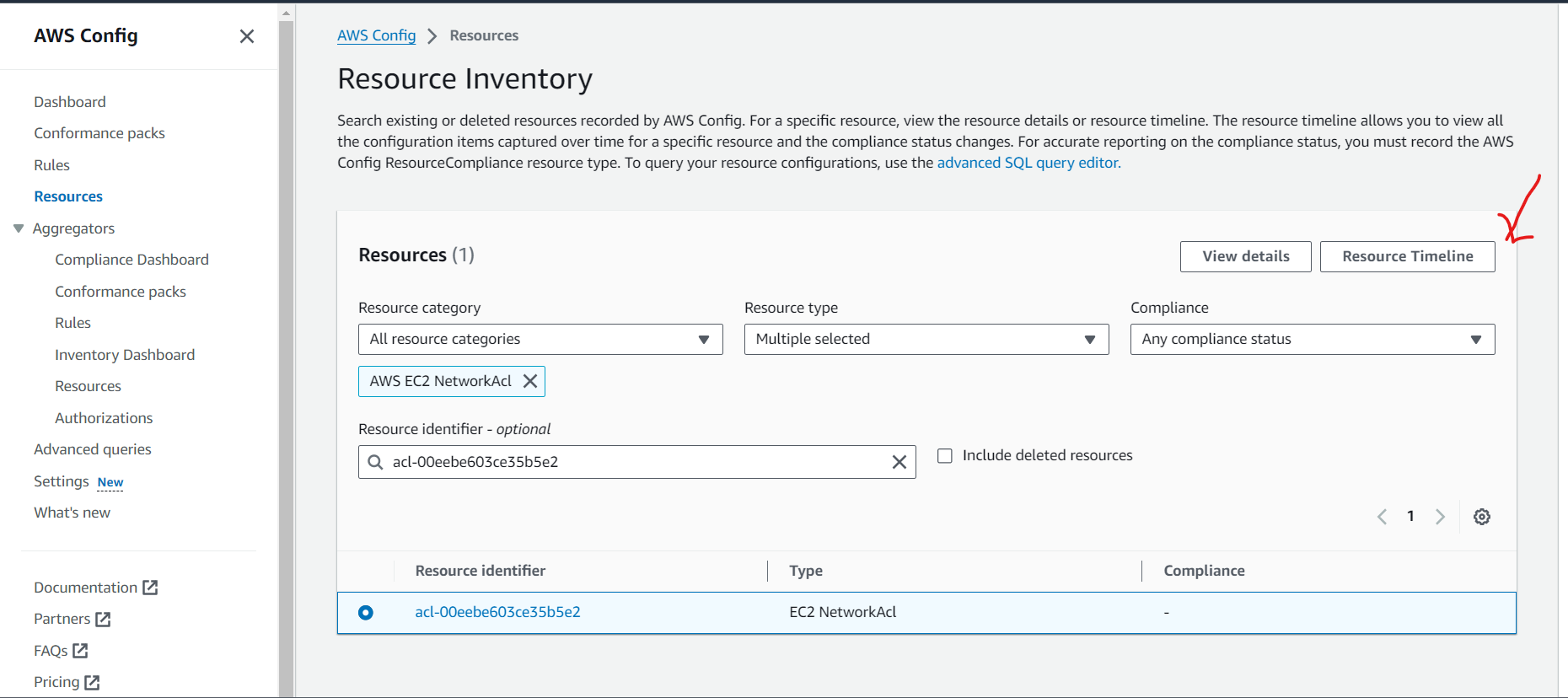
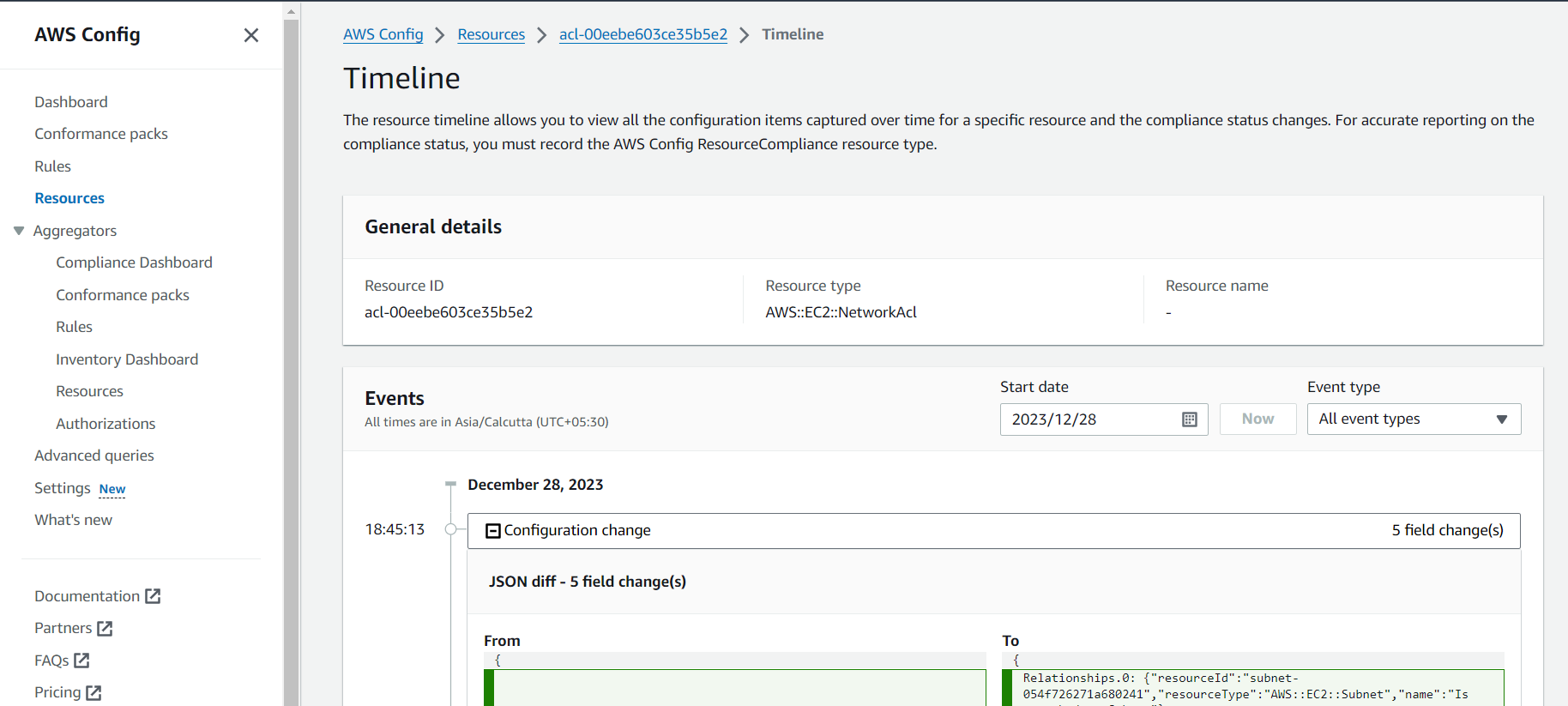
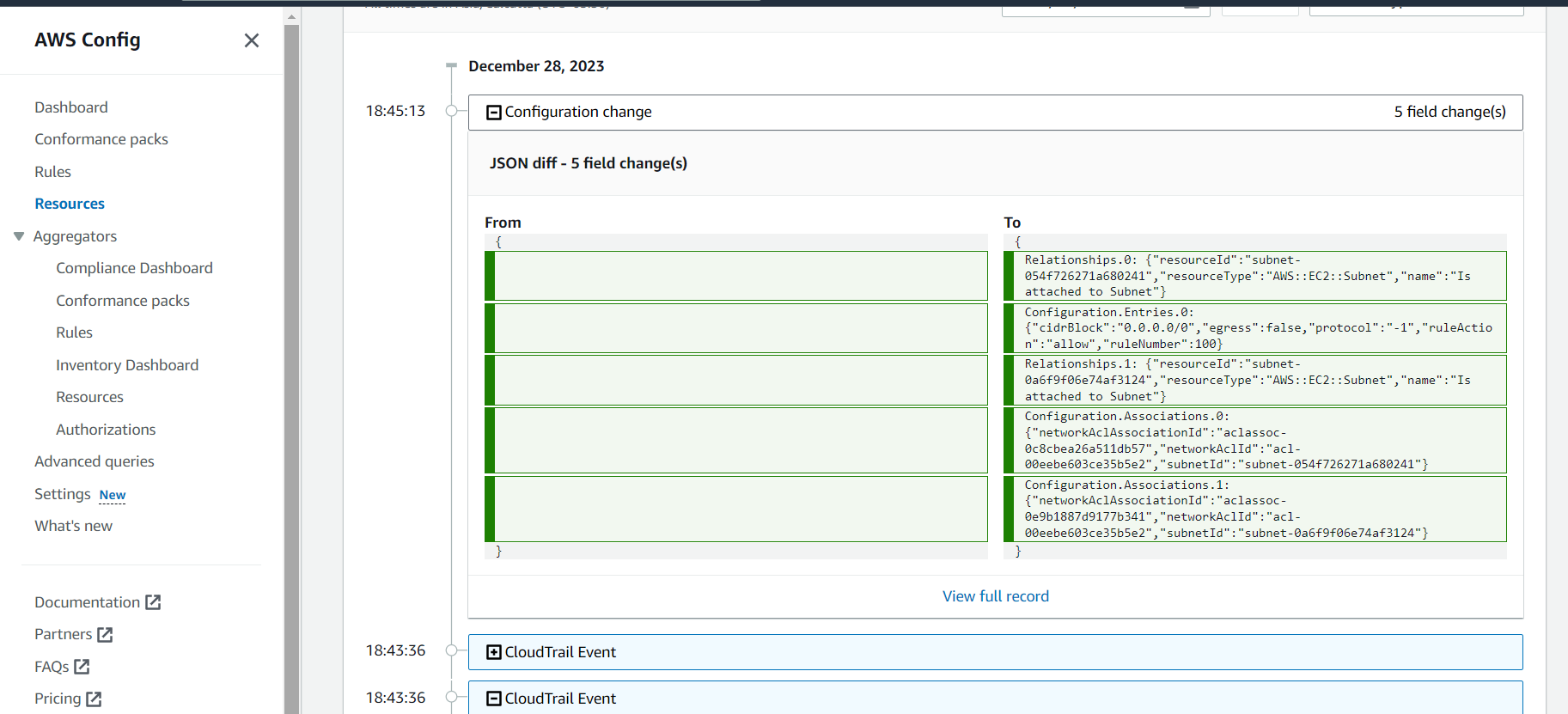
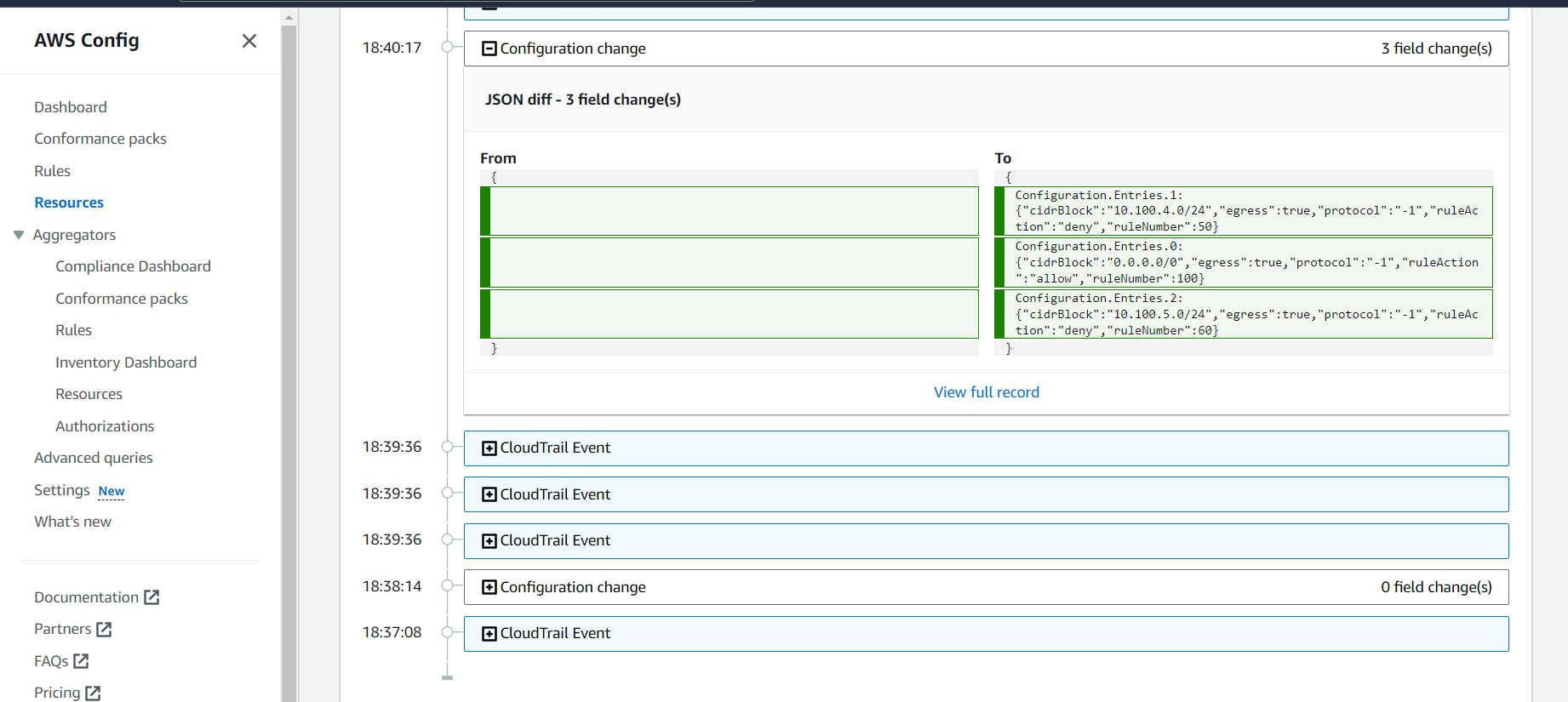
Apply granular logging.
Improve granular control of communication.
Improve granular network-based controls.
Evaluate detailed logging capabilities.
Some other examples for Security Pillar
Network Security: Set up a VPC with private and public subnets, use security groups to control inbound and outbound traffic, and configure Network Access Control Lists (NACLs) for additional network layer security.
Identity and Access Management (IAM): Implement IAM roles, policies, and groups to control access to AWS resources.
Encryption: Enable encryption in transit using SSL/TLS for applications and services. Implement encryption at rest using services like AWS KMS for managing encryption keys.
Security Monitoring and Incident Response: Set up CloudWatch Alarms and AWS Config Rules to detect and alert on security incidents.
🔶 Outcome:
🔹 VPC architecture with private and public subnets is established.
🔹 Security groups and NACLs configured for enhanced network security.
🔹 IAM roles, policies, and groups implemented for access management.
Performance Efficiency Pillar
It focuses on optimizing performance and efficiency by selecting the right resources and configurations based on the unique requirements of your workload. The goal is to deliver cost-effective solutions that meet performance requirements
💠 AnyCompany wants to optimize performance and efficiency by implementing auto-scaling and conducting stress tests to validate the scalability of its application.
Key Principles:
Use Cost-Effective Resources: Choose the right instance types and sizes based on your workload's specific requirements. Use services like AWS Cost Explorer to analyze and optimize costs associated with different resource choices.
Match Supply with Demand: Implement auto-scaling to automatically adjust the number of resources based on demand. This ensures that you have the right amount of resources available to handle varying workloads.
Go Global in Minutes: Leverage AWS services like Amazon CloudFront, Amazon S3 Transfer Acceleration, and AWS Global Accelerator to distribute content and applications globally, reducing latency and improving performance for end-users worldwide.
Experiment More Often: Use AWS services like AWS Lambda or Amazon ECS to deploy and test new features without the need to provision and manage additional infrastructure. This allows for rapid experimentation and innovation.
Based upon this example we can implement below points to follow the performance efficiency pillar
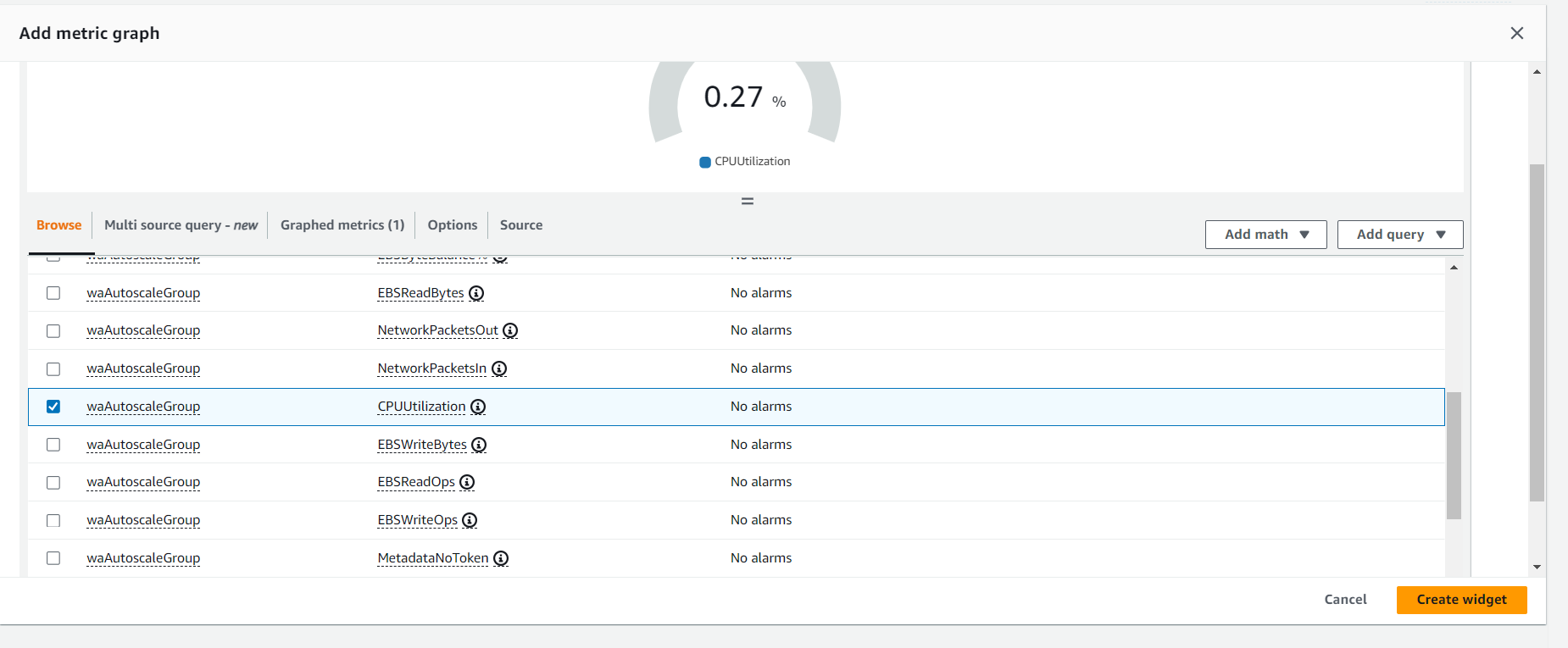
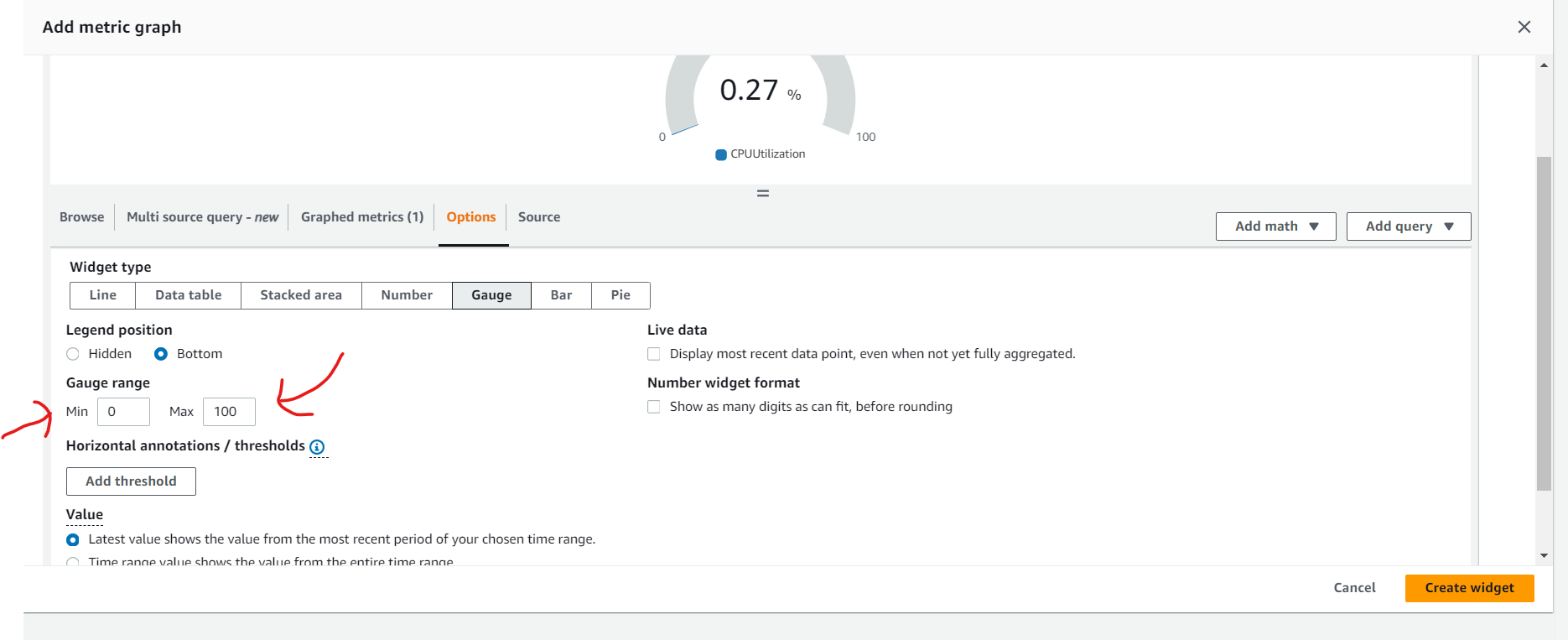
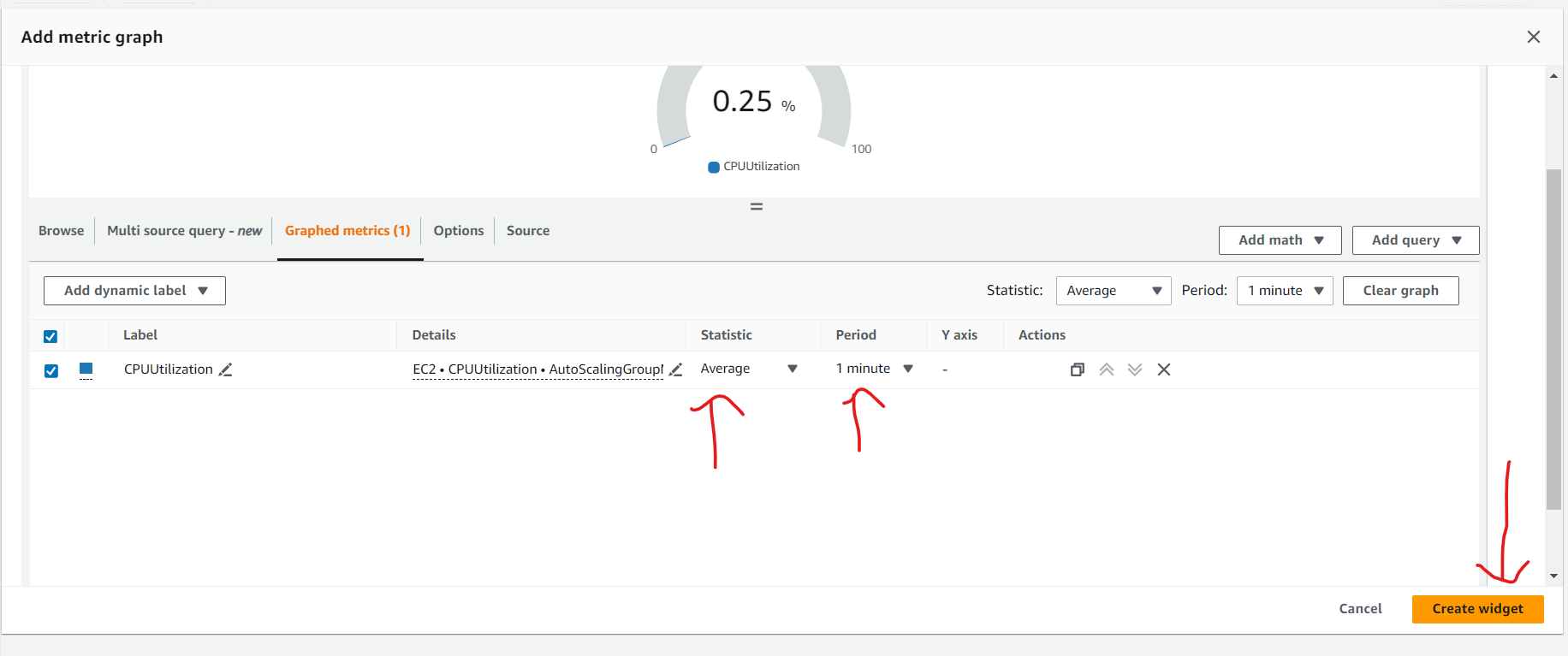
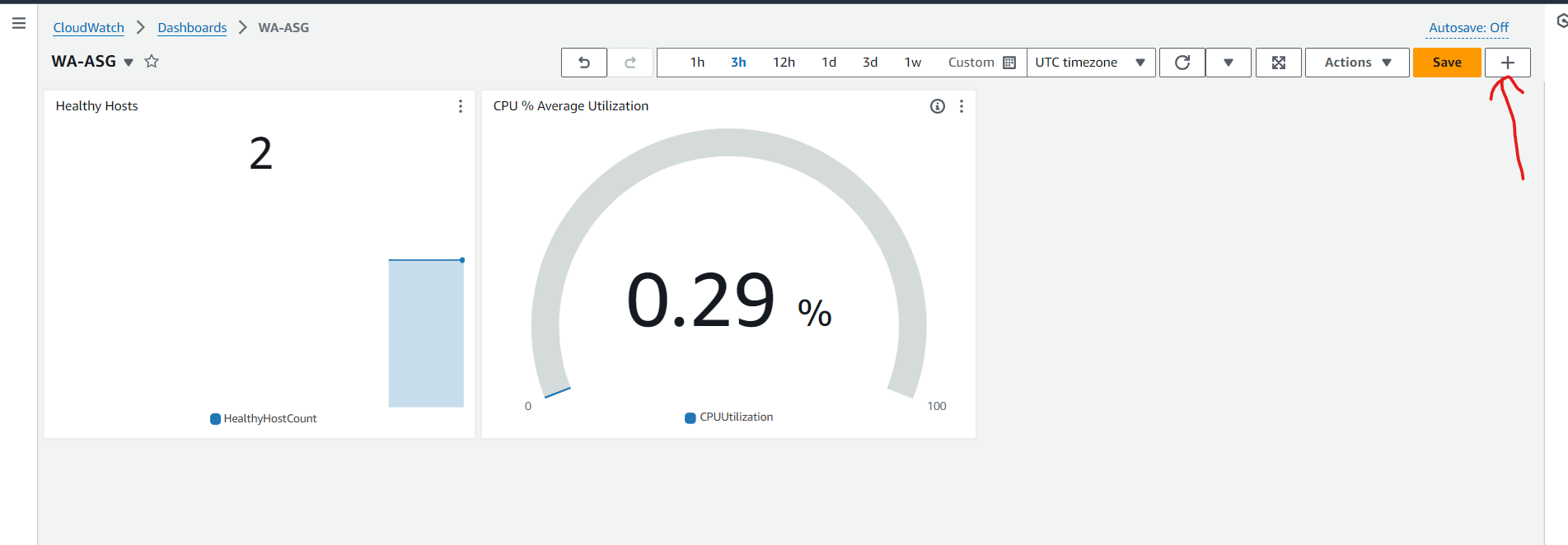
- Create target tracking scaling policies for an Amazon EC2 Auto Scaling group.
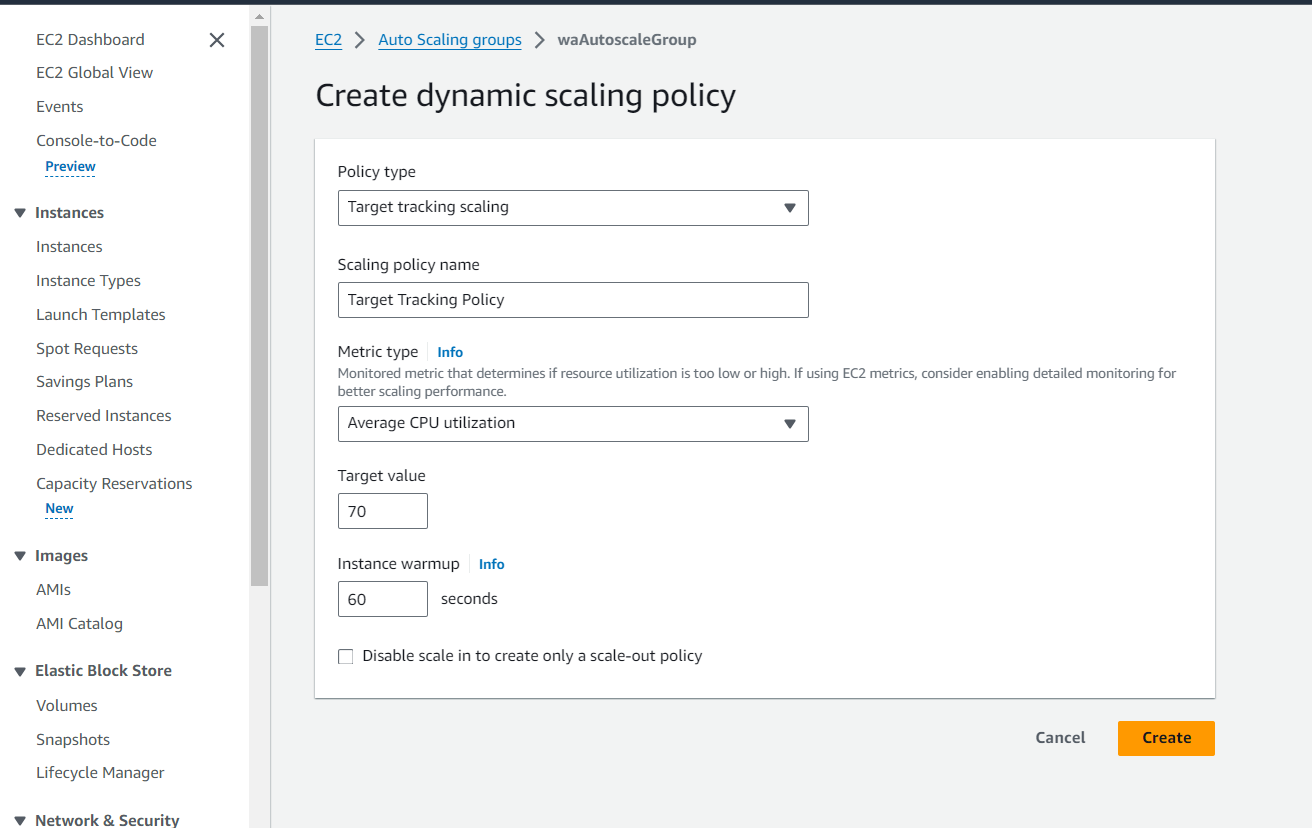
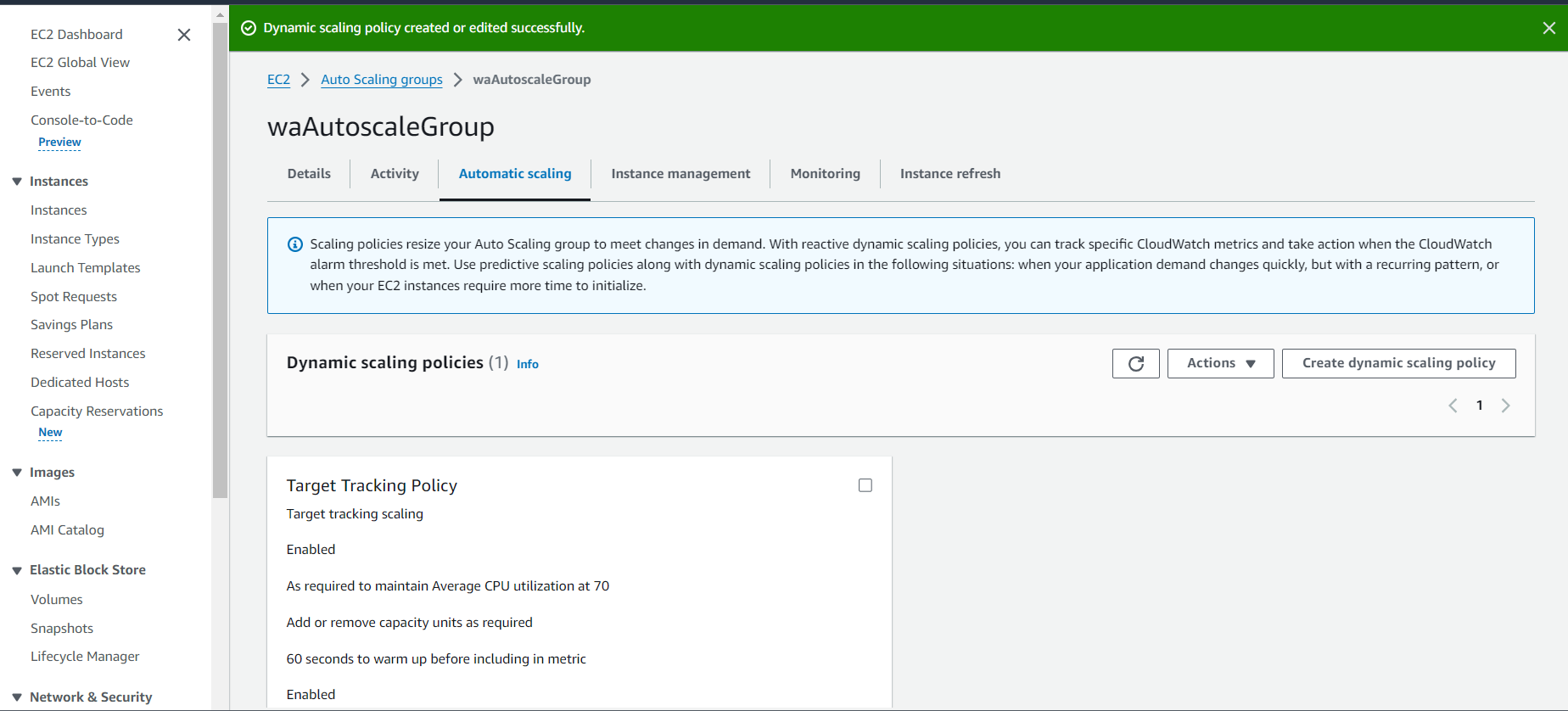
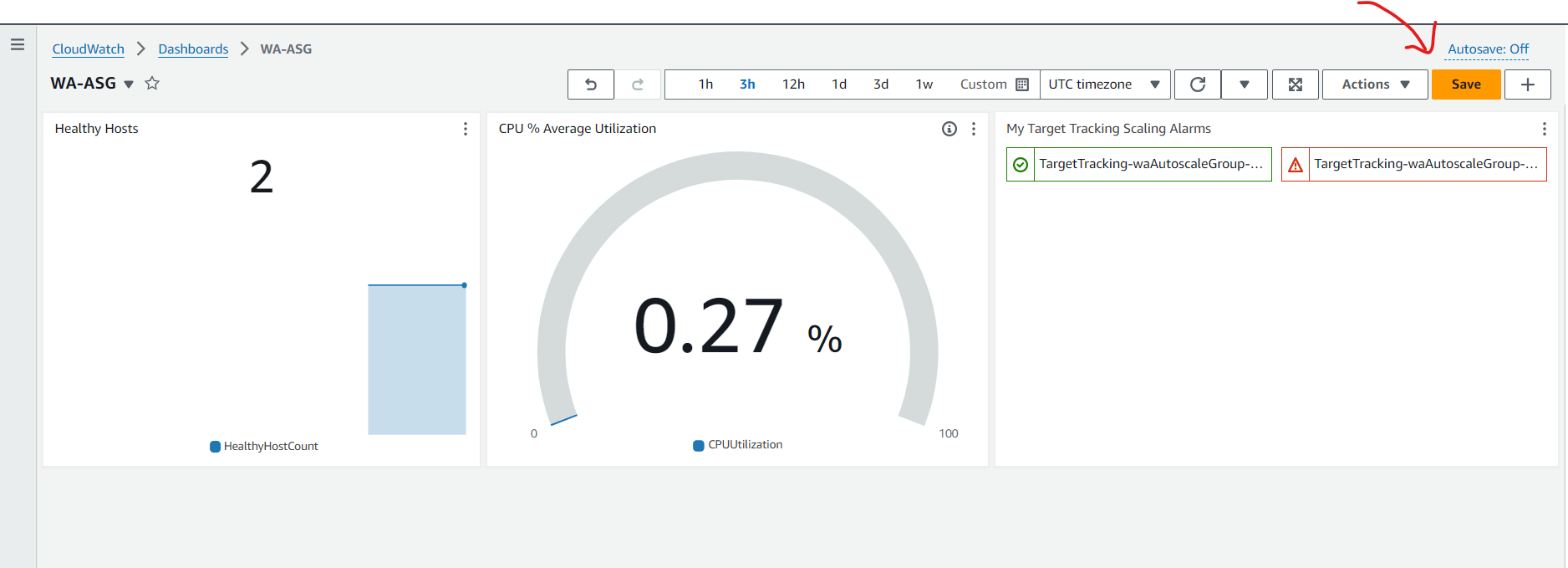
Create a customized Amazon CloudWatch dashboard.
Perform a stress test to validate the scaling policy.
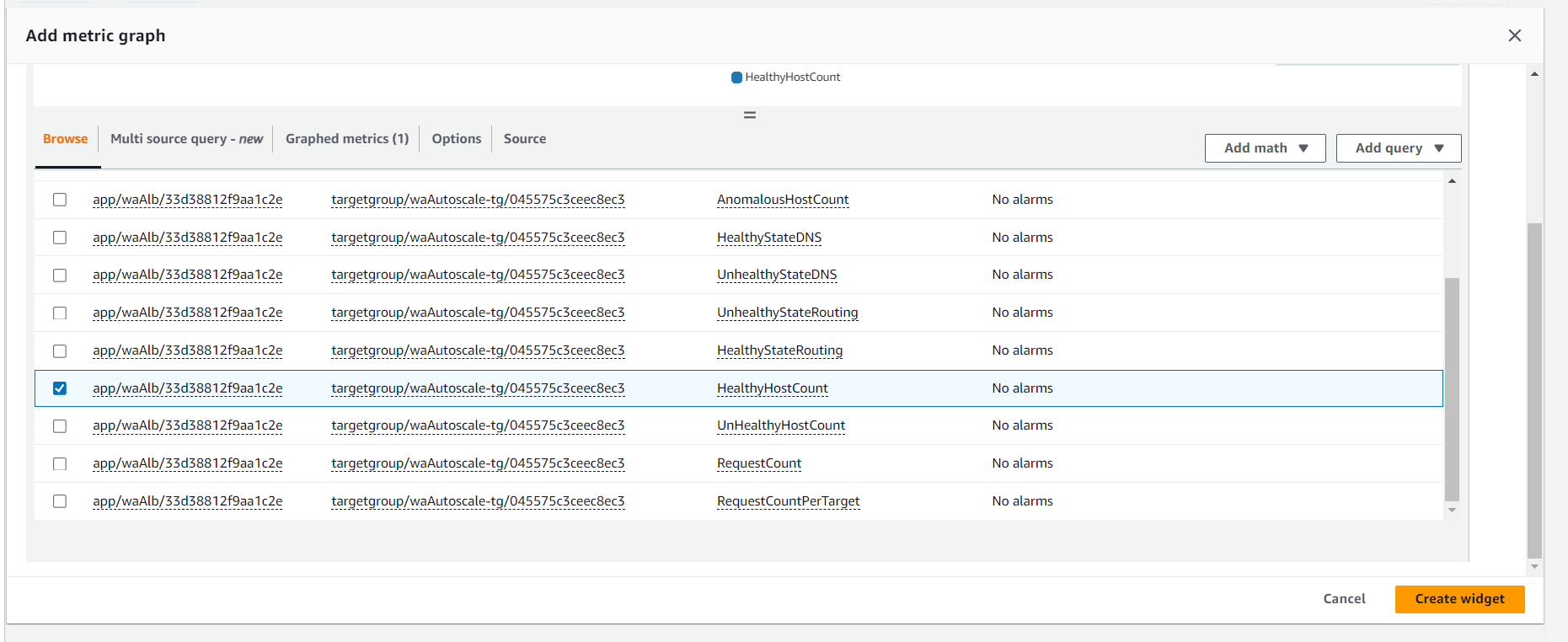
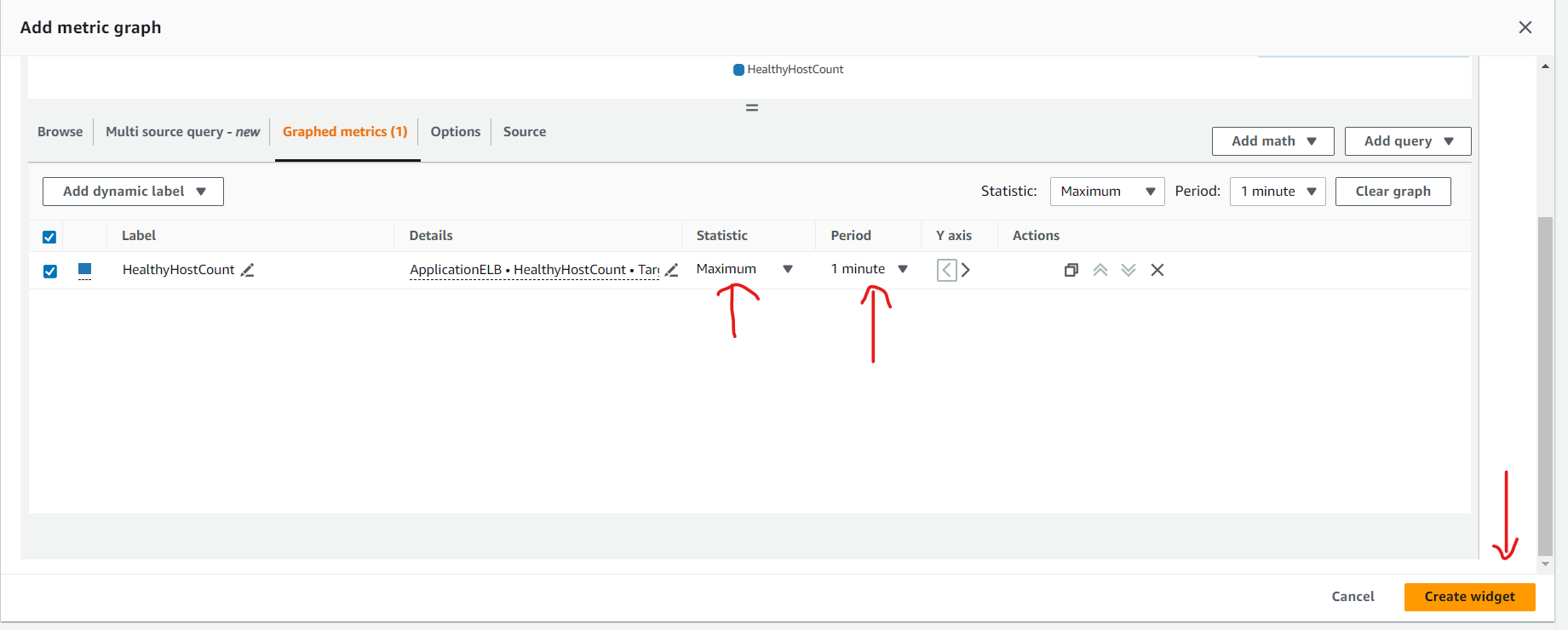
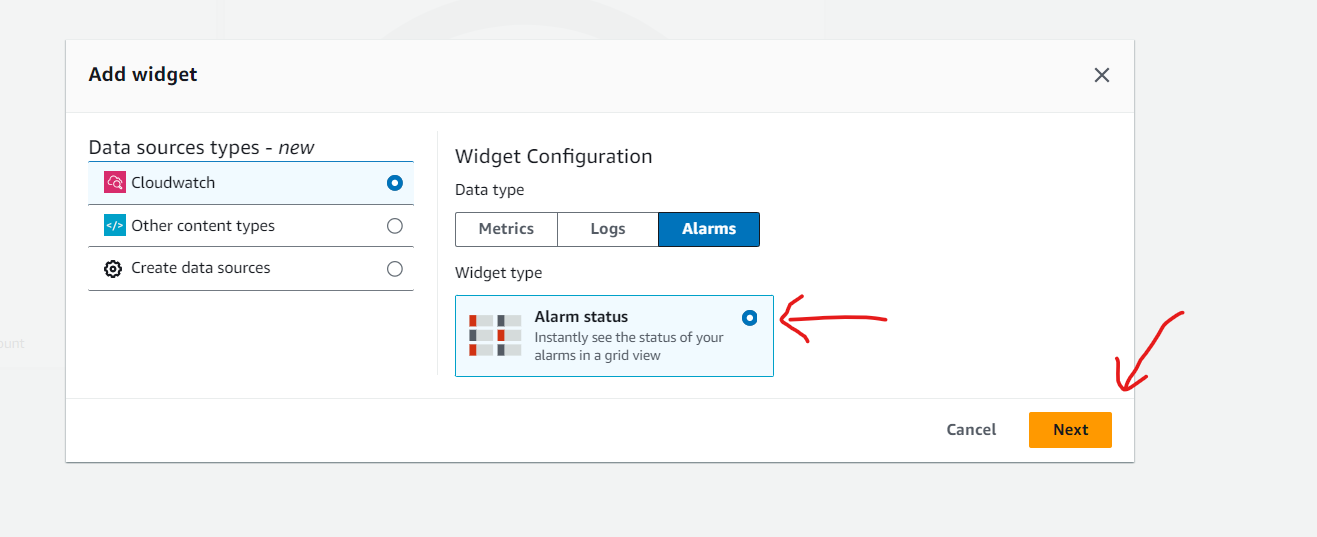
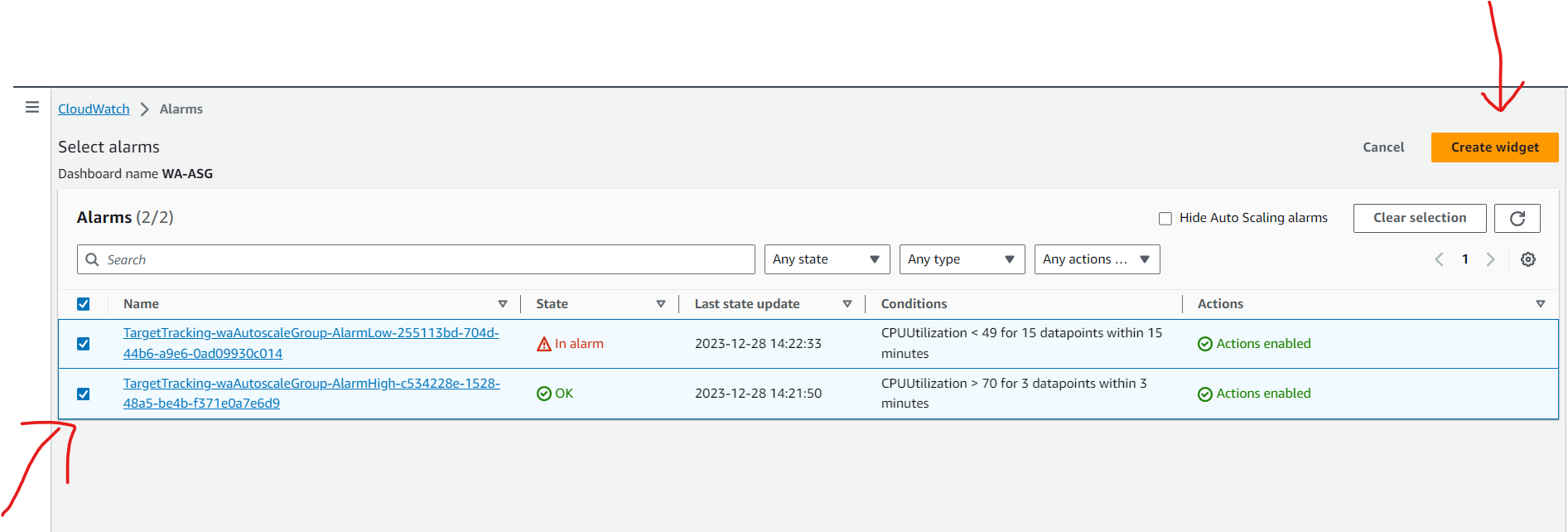
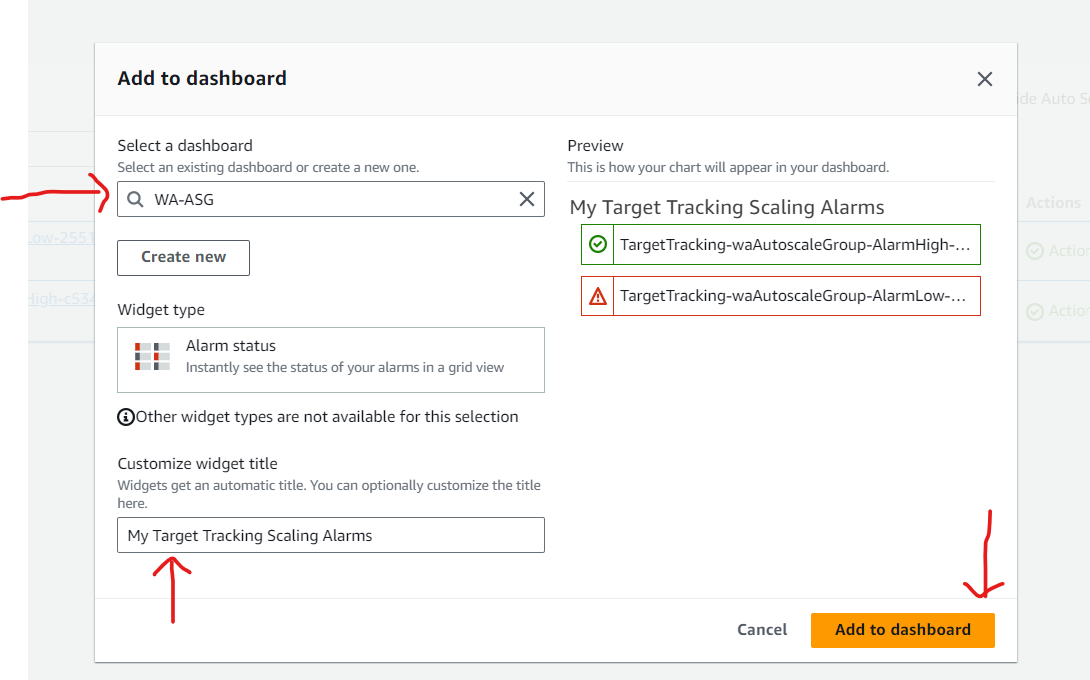
Some other examples for Performance Efficiency Pillar
Auto-Scaling: Implement auto-scaling groups to automatically adjust the number of Amazon EC2 instances based on demand.
Elastic Load Balancing: Use Elastic Load Balancing (ELB) to distribute incoming traffic across multiple instances, ensuring that workloads are balanced and that your application can scale horizontally.
Serverless Architectures: Leverage serverless computing with AWS Lambda to execute code in response to events without provisioning or managing servers.
Caching and Content Delivery: Implement caching mechanisms using services like Amazon ElastiCache or CloudFront to reduce latency and improve the performance of applications by serving content from edge locations closer to end-users.
Amazon RDS Performance Tuning: Optimize the performance of relational databases by adjusting parameters, selecting appropriate instance types, and using features like Multi-AZ deployment for high availability.
Amazon S3 Storage Classes: Use different storage classes in Amazon S3, such as Standard, Intelligent-Tiering, Glacier, etc., based on the access patterns and requirements of your data. This helps optimize costs and performance.
Amazon Aurora Auto-Scaling: Configure auto-scaling for Amazon Aurora to automatically adjust the database cluster's capacity based on the actual workload.
🔶 Outcome:
🔹 Auto-scaling policies adjust the number of EC2 instances based on demand.
🔹 CloudWatch dashboard provides real-time visibility into application performance.
🔹 Application successfully scales horizontally during stress tests.
Cost Optimization Pillar
It focuses on managing and optimizing costs to get the best value out of your AWS resources. The goal is to avoid unnecessary expenses, scale efficiently, and continuously improve cost-effectiveness.
💠 AnyCompany aims to optimize costs by implementing AWS Config Rules and applying preventative controls for compliance.
Key Principles:
Adopt a Consumption Model: Use on-demand or reserved pricing for resources based on your application's characteristics. For variable workloads, consider using spot instances to take advantage of lower costs.
Measure Overall Efficiency: Regularly monitor and analyze key performance metrics, cost metrics, and other efficiency indicators using AWS Cost Explorer, AWS Budgets, and AWS Trusted Advisor.
Stop Spending Money on Data Center Operations: Migrate from traditional on-premises data centers to AWS to leverage the pay-as-you-go model and avoid upfront capital expenses.
Analyze and Attributing Expenditure: Tag your AWS resources appropriately to attribute costs to specific projects, teams, or departments. Use resource tagging to understand and optimize costs at a granular level.
Use Managed Services to Reduce Cost of Ownership: Consider using managed services like Amazon RDS instead of self-managed databases. Managed services often reduce operational overhead and provide cost savings compared to maintaining your infrastructure.
Based upon this example we can implement below points to follow the performance efficiency pillar
Create AWS Config rules.
Review and remediate AWS Config findings.
Apply preventative controls for compliance.
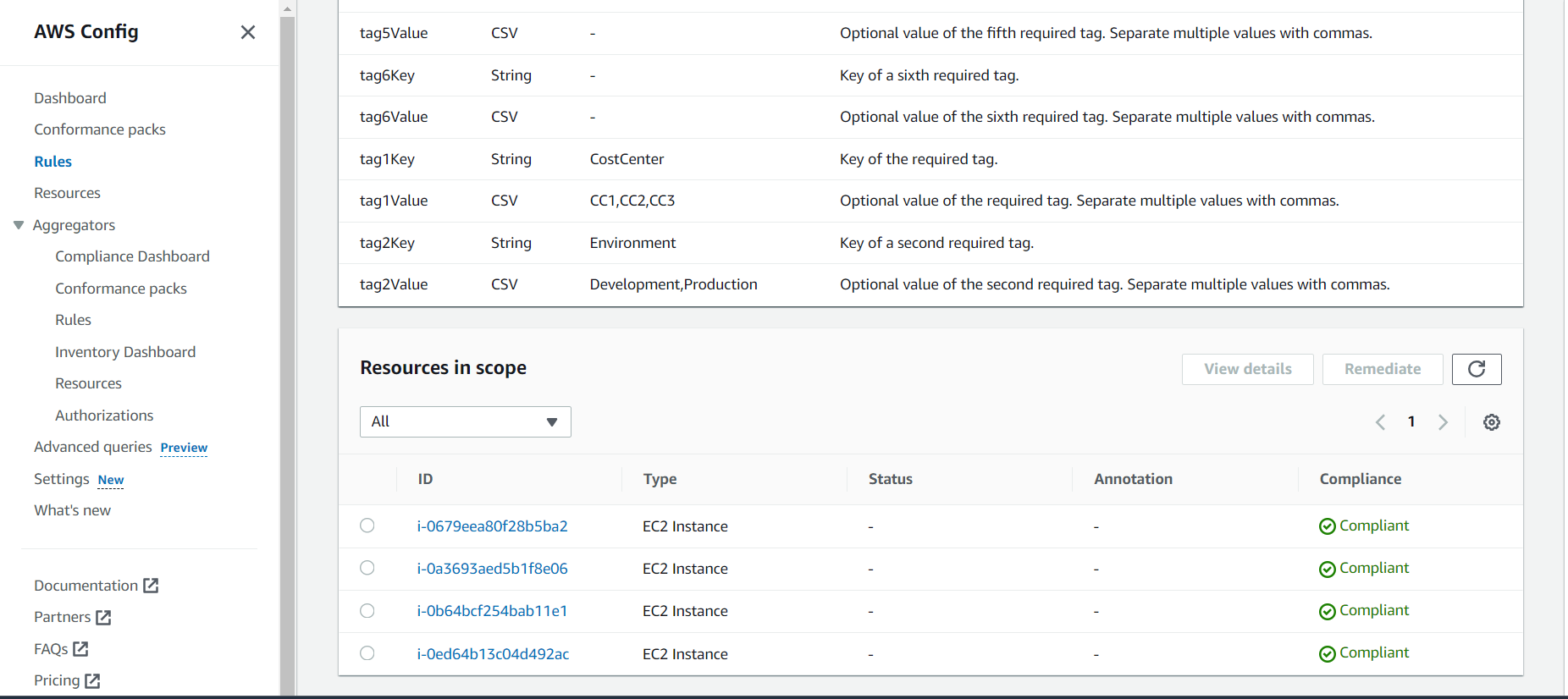
The below example is one of the easiest way to understand quickly about aws config rules
We can add this policy to the group so it will applicable to all users in that group. This policy will make restrictions when creating new resources
ex: When creating EC2 instance everyone should add only specific tags like environment and etc.. and select on t3.small instance type if they selecting those configurations if we add this policy to the group automatically creating EC2 instance will fail.(Not only this policy we can customize based upon our requirement)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": ["ec2:Describe*"],
"Resource": "*",
"Effect": "Allow",
"Sid": "AllowToDescribeAll"
},
{
"Action": ["ec2:RunInstances", "ec2:CreateVolume"],
"Resource": [
"arn:aws:ec2:*::image/*",
"arn:aws:ec2:*::snapshot/*",
"arn:aws:ec2:*:*:subnet/*",
"arn:aws:ec2:*:*:network-interface/*",
"arn:aws:ec2:*:*:security-group/*",
"arn:aws:ec2:*:*:key-pair/*",
"arn:aws:ec2:*:*:volume/*"
],
"Effect": "Allow",
"Sid": "AllowRunInstances"
},
{
"Condition": {
"StringEquals": {
"aws:RequestTag/CostCenter": "CC1",
"aws:RequestTag/Environment": "Development",
"ec2:InstanceType": "t3.small"
}
},
"Action": ["ec2:RunInstances"],
"Resource": ["arn:aws:ec2:*:*:instance/*"],
"Effect": "Allow",
"Sid": "AllowRunInstancesWithRestrictions"
},
{
"Condition": {
"StringEquals": {
"ec2:CreateAction": "RunInstances"
}
},
"Action": ["ec2:CreateTags"],
"Resource": ["arn:aws:ec2:*:*:volume/*", "arn:aws:ec2:*:*:instance/*", "arn:aws:ec2:*:*:network-interface/*"],
"Effect": "Allow",
"Sid": "AllowCreateTagsOnlyLaunching"
}
]
}
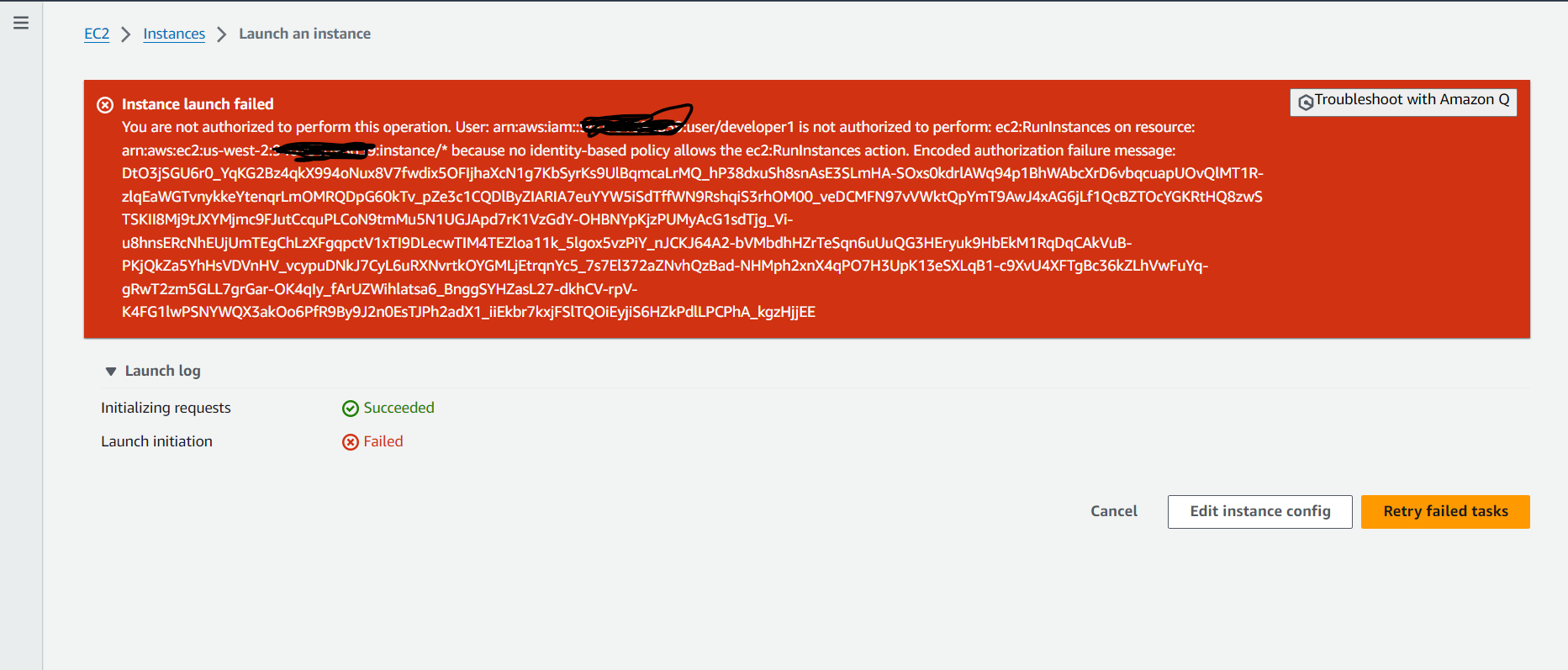
- Here I launched EC2 instance with given Environment value as Dev instead of Development, so automatically it failed to launch the instance.
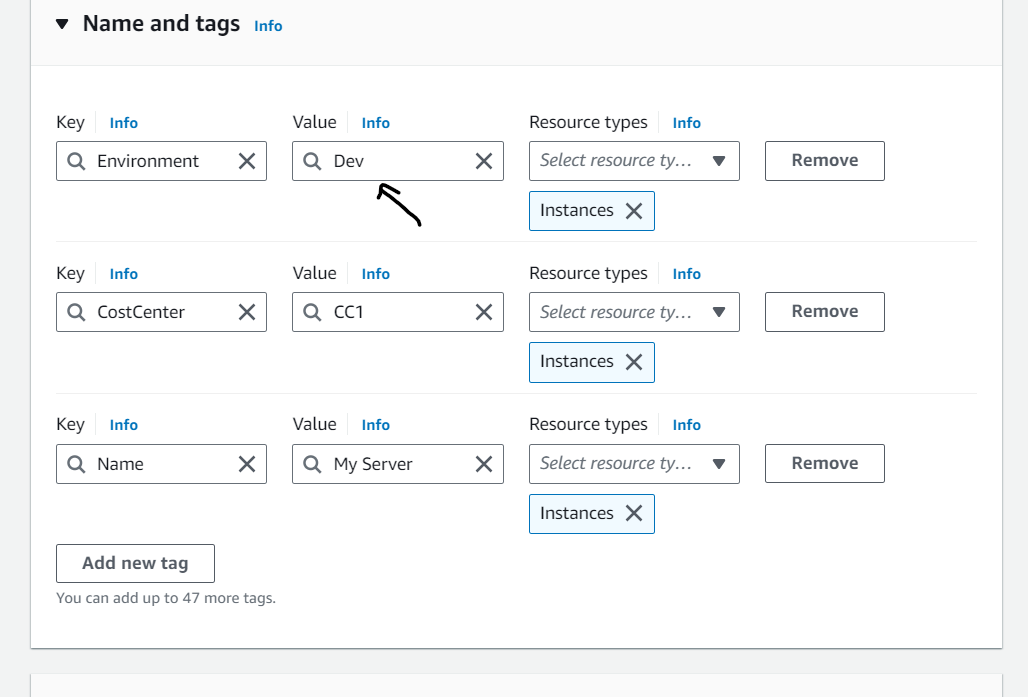
- When i updated the value from Dev to Development automatically it launched an EC2 instance.
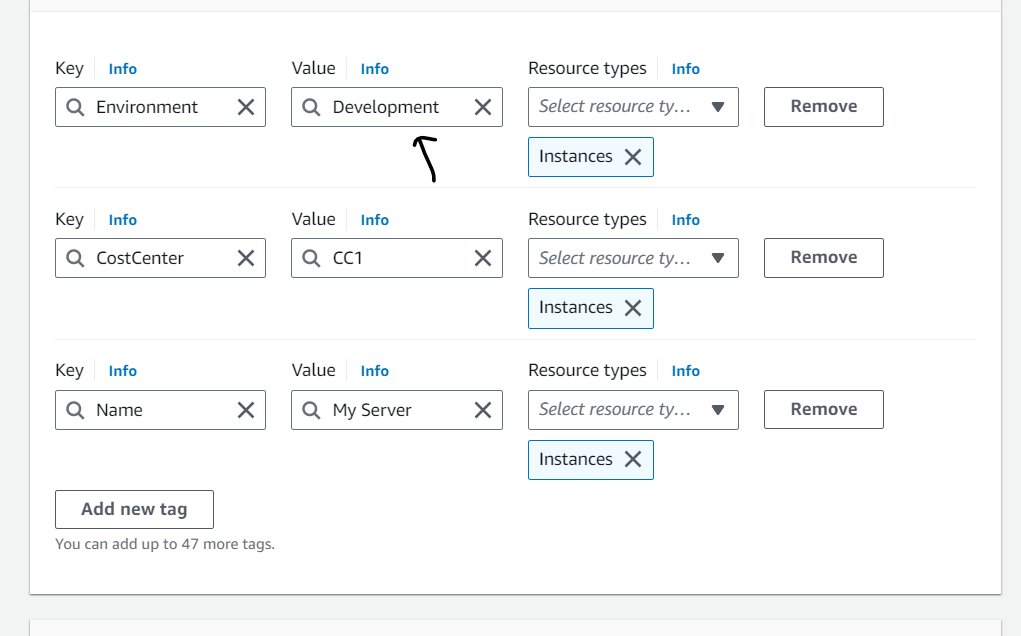
When creating aws config rules if any of the condition in the rule not satisfied automatically here the resource status will go to non-compliant.
Once all conditions in that rule satisfies automatically it will go to compliant state.
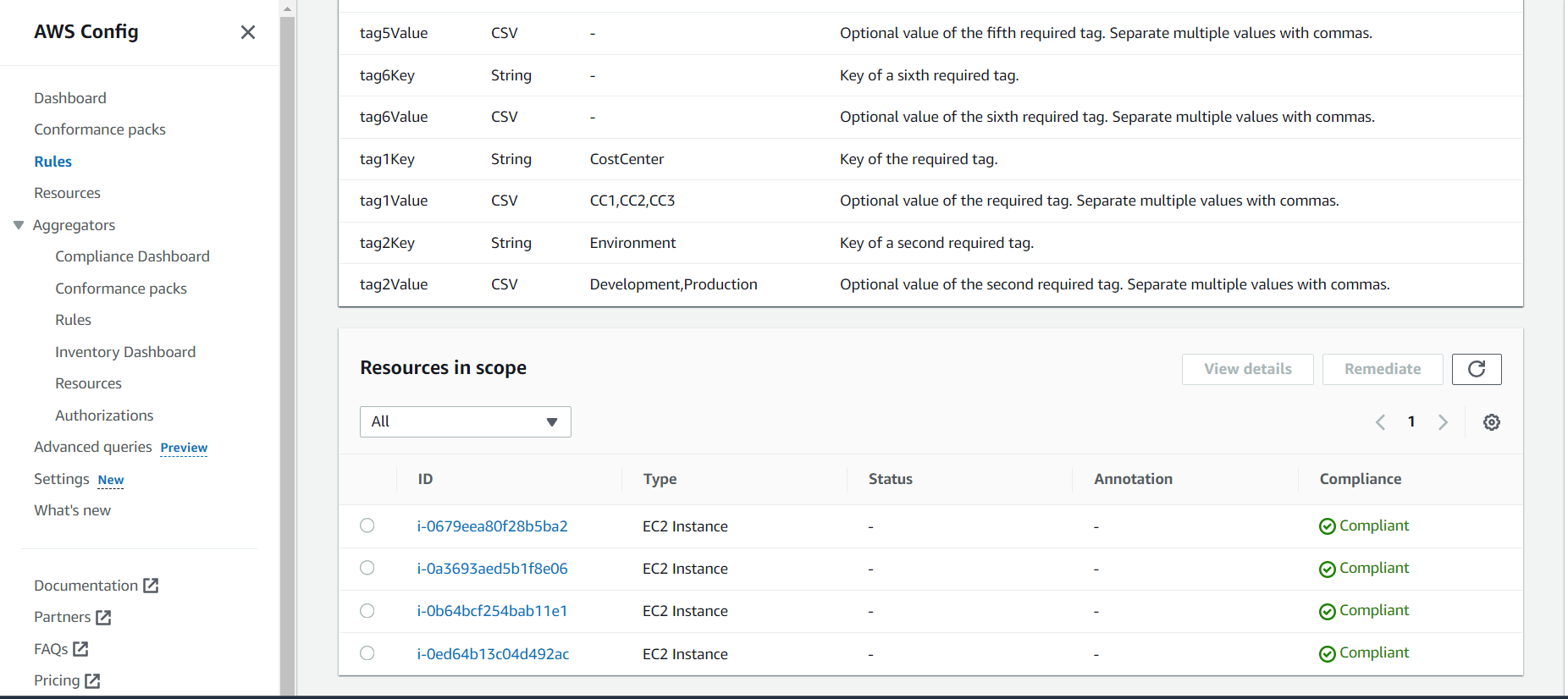
🔶 Outcome:
🔹 AWS Config rules continuously monitor resource configurations.
🔹 Findings are reviewed and remediated to maintain compliance.
🔹 Preventative controls help in avoiding unnecessary costs.